

Synthetic data, artificially created rather than sourced from real-world events, has emerged as a critical tool in the contemporary landscape of data science and artificial intelligence, addressing pressing concerns related to privacy, data scarcity, and cost. This innovative approach allows developers and researchers to construct datasets that mirror the statistical properties and patterns of genuine information without exposing sensitive details, thereby facilitating robust software testing, model training, and experimental simulations. While sophisticated external libraries like Faker, SDV, and SynthCity, alongside large language models (LLMs), offer powerful automated solutions for synthetic data generation, a foundational understanding of crafting these datasets through custom Python scripts provides unparalleled control and insight into data shaping, potential biases, and inherent structures. This article delves into various methods for generating synthetic data using pure Python, offering a practical pathway to mastering a crucial skill in the age of data-driven innovation.
The Growing Imperative for Synthetic Data in a Data-Driven World
The demand for synthetic data is not merely a technical preference but a strategic imperative driven by a confluence of regulatory pressures, economic realities, and the accelerating pace of AI development. In an era marked by heightened awareness of data privacy, regulations such as the General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA) in the United States, and similar frameworks worldwide impose stringent requirements on how personal data is collected, processed, and stored. Non-compliance can lead to severe penalties, including substantial fines, reputational damage, and legal repercussions. For instance, GDPR fines can reach up to €20 million or 4% of annual global turnover, whichever is higher, creating a significant deterrent for organizations handling sensitive information.
Against this backdrop, real-world data, particularly in sensitive sectors like healthcare, finance, or government, often comes with prohibitive acquisition costs, complex anonymization procedures, and intricate legal hurdles. Accessing sufficient volumes of diverse, high-quality real data for training complex machine learning models can be a bottleneck for innovation. Synthetic data offers a viable alternative, enabling organizations to generate large, diverse datasets on demand, significantly reducing data collection expenses and accelerating development cycles. A recent report by Gartner predicted that by 2030, synthetic data will completely overshadow real data in AI models, underscoring its transformative potential. Furthermore, synthetic data plays a vital role in addressing issues of data imbalance and bias. By programmatically generating samples for underrepresented classes or scenarios, developers can create more equitable and robust training datasets, leading to fairer and more accurate AI systems. This controlled environment also allows for the simulation of rare events or "edge cases" that might be scarce in real data, improving the resilience and reliability of deployed models.

Mastering Synthetic Data Generation with Python Scripts
Python’s extensive ecosystem and readability make it an ideal language for developing custom synthetic data generators. The act of writing these scripts from scratch, rather than relying on black-box tools, provides data scientists and engineers with a profound understanding of the underlying mechanisms that govern data distribution, correlations, and potential pitfalls. This hands-on approach illuminates how biases can inadvertently be introduced or how specific data patterns emerge, equipping practitioners with the knowledge to create more sophisticated and trustworthy synthetic datasets.
1. Generating Tabular Data: From Randomness to Realism
The simplest form of synthetic data generation begins with creating tabular datasets, such as a mock customer database for internal testing or demonstrations. Initially, one might employ basic random number generation for each field independently. For example, a script could generate customer IDs, ages within a range, randomly selected countries, subscription plans, and monthly spending.
import csv
import random
from datetime import datetime, timedelta
random.seed(42) # For reproducibility
countries = ["Canada", "UK", "UAE", "Germany", "USA"]
plans = ["Free", "Basic", "Pro", "Enterprise"]
def random_signup_date():
start = datetime(2024, 1, 1)
end = datetime(2026, 1, 1)
delta_days = (end - start).days
return (start + timedelta(days=random.randint(0, delta_days))).date().isoformat()
rows = []
for i in range(1, 1001):
age = random.randint(18, 70)
country = random.choice(countries)
plan = random.choice(plans)
monthly_spend = round(random.uniform(0, 500), 2)
rows.append(
"customer_id": f"CUSTi:05d",
"age": age,
"country": country,
"plan": plan,
"monthly_spend": monthly_spend,
"signup_date": random_signup_date()
)
# Code to write to CSV (as in original article)While functional, this purely random approach often yields data that lacks natural coherence. A "Free" plan user might coincidentally have a higher monthly spend than an "Enterprise" user, or younger customers might exhibit identical spending habits to older ones, which is atypical in real-world scenarios. This flat distribution can limit the utility of the synthetic data for training models that rely on identifying complex relationships.
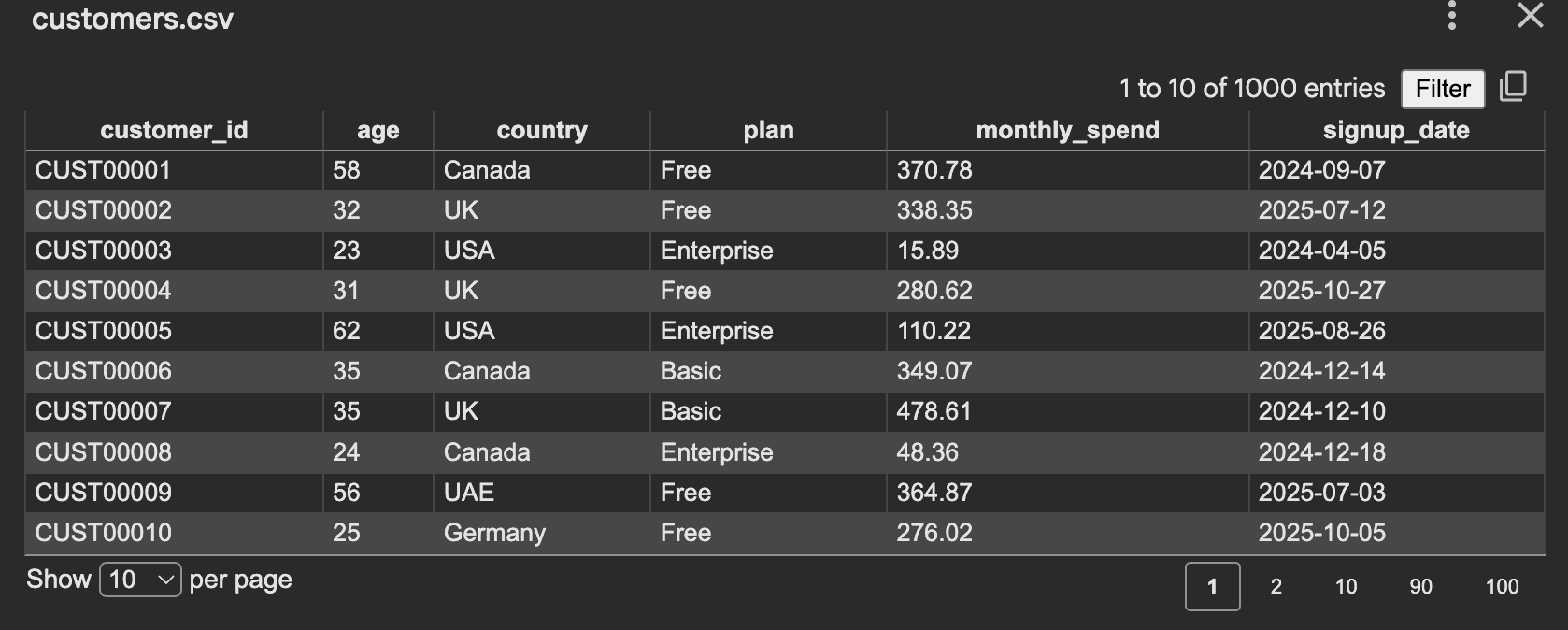
To enhance realism, it becomes crucial to introduce controlled randomness by embedding logical dependencies and weighted distributions. For instance, subscription plans typically follow a power-law distribution, with a higher proportion of free or basic users. Monthly spending should correlate with the chosen plan and potentially other demographic factors like age or country.
import csv
import random
random.seed(42)
plans = ["Free", "Basic", "Pro", "Enterprise"]
def choose_plan():
roll = random.random() # Random float between 0.0 and 1.0
if roll < 0.45: # 45% Free
return "Free"
if roll < 0.75: # 30% Basic (0.75 - 0.45)
return "Basic"
if roll < 0.93: # 18% Pro (0.93 - 0.75)
return "Pro"
return "Enterprise" # 7% Enterprise
def generate_spend(age, plan):
# Base spend varies significantly by plan
if plan == "Free":
base = random.uniform(0, 10)
elif plan == "Basic":
base = random.uniform(10, 60)
elif plan == "Pro":
base = random.uniform(50, 180)
else: # Enterprise
base = random.uniform(150, 500)
# Age as a factor: older customers might spend more
if age >= 40:
base *= 1.15 # 15% uplift for older customers
# Introduce some country-specific variation (hypothetical)
# if country == "USA":
# base *= random.uniform(0.9, 1.2) # Example: USA has wider spend range
return round(base, 2)
rows = []
for i in range(1, 1001):
age = random.randint(18, 70)
plan = choose_plan()
spend = generate_spend(age, plan) # Now depends on age and plan
rows.append(
"customer_id": f"CUSTi:05d",
"age": age,
"plan": plan,
"monthly_spend": spend
)
# Code to write to CSV (as in original article)This controlled approach produces a dataset where logical patterns are preserved, making the synthetic data far more useful for training predictive models, conducting exploratory data analysis, or stress-testing reporting dashboards. Effective controls can include conditional probability distributions, age-based modifiers, geographical variations, or time-dependent trends.
2. Simulating Dynamic Systems for Realistic Data
Beyond static tabular data, one of the most effective methods for generating realistic synthetic datasets involves simulating processes. Instead of directly populating columns with random values, data is generated as a byproduct of a modeled system’s behavior. This approach naturally imbues the data with complex, emergent relationships that are often difficult to define explicitly.
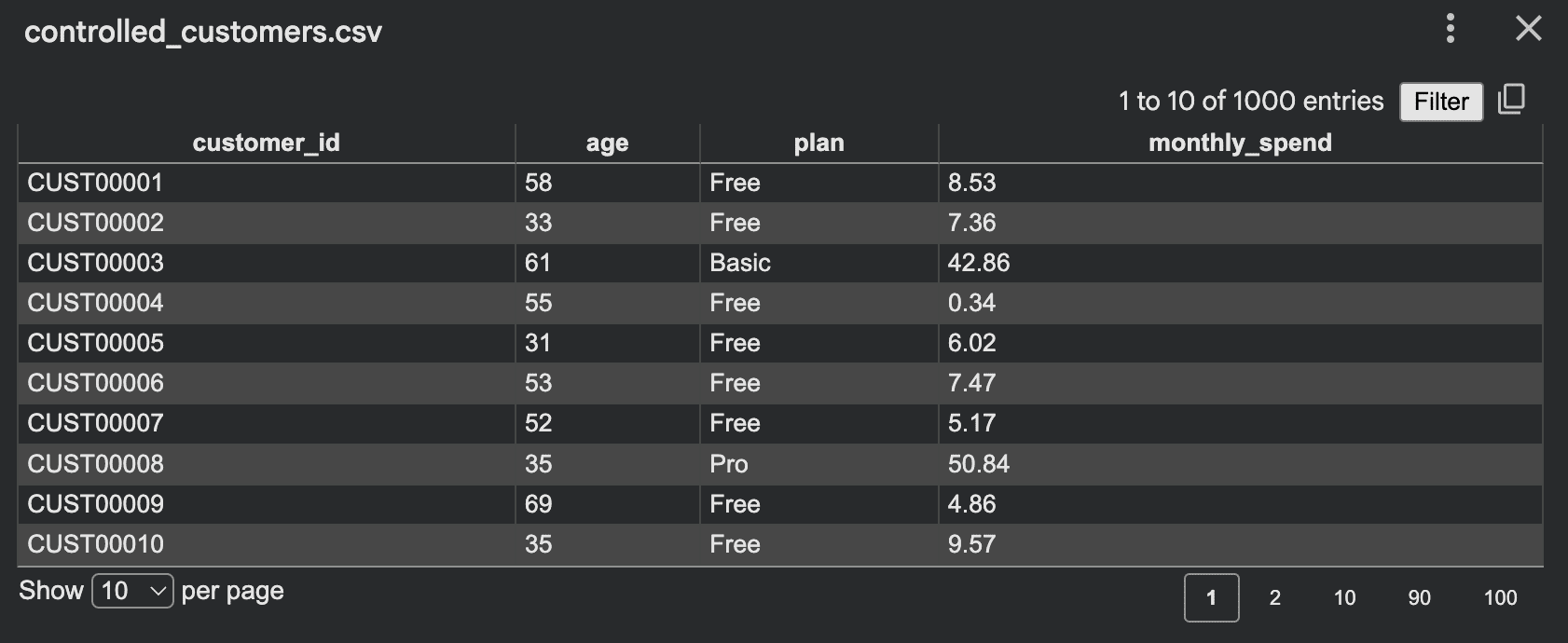
Consider the example of a small warehouse inventory system. Orders arrive, stock levels fluctuate, and low stock triggers restocks. Simulating these interactions over time generates a rich dataset reflecting operational dynamics:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
inventory =
"A": 120, # Initial stock for product A
"B": 80,
"C": 50
rows = []
current_time = datetime(2026, 1, 1)
for day in range(30): # Simulate 30 days
for product in inventory:
daily_orders = random.randint(0, 12) # Random number of orders per day per product
for _ in range(daily_orders):
qty = random.randint(1, 5) # Order quantity
before = inventory[product]
if inventory[product] >= qty:
inventory[product] -= qty
status = "fulfilled"
else:
status = "backorder" # Not enough stock
rows.append(
"time": current_time.isoformat(),
"product": product,
"qty": qty,
"stock_before": before,
"stock_after": inventory[product],
"status": status
)
# Check for restock condition
if inventory[product] < 20:
restock = random.randint(30, 80)
inventory[product] += restock
rows.append(
"time": current_time.isoformat(),
"product": product,
"qty": restock,
"stock_before": inventory[product] - restock,
"stock_after": inventory[product],
"status": "restock"
)
current_time += timedelta(days=1) # Advance time
# Code to write to CSV (as in original article)This simulation yields data where "stock_after" is directly dependent on "stock_before" and "qty," and "status" is a consequence of inventory levels. Such intricate relationships are invaluable for training predictive models for supply chain optimization, demand forecasting, or anomaly detection in operational data. Other simulation ideas include modeling customer journeys through a website, simulating network traffic patterns, or even biological processes, each generating data that inherently reflects system behavior.
3. Crafting Time Series Data with Temporal Patterns
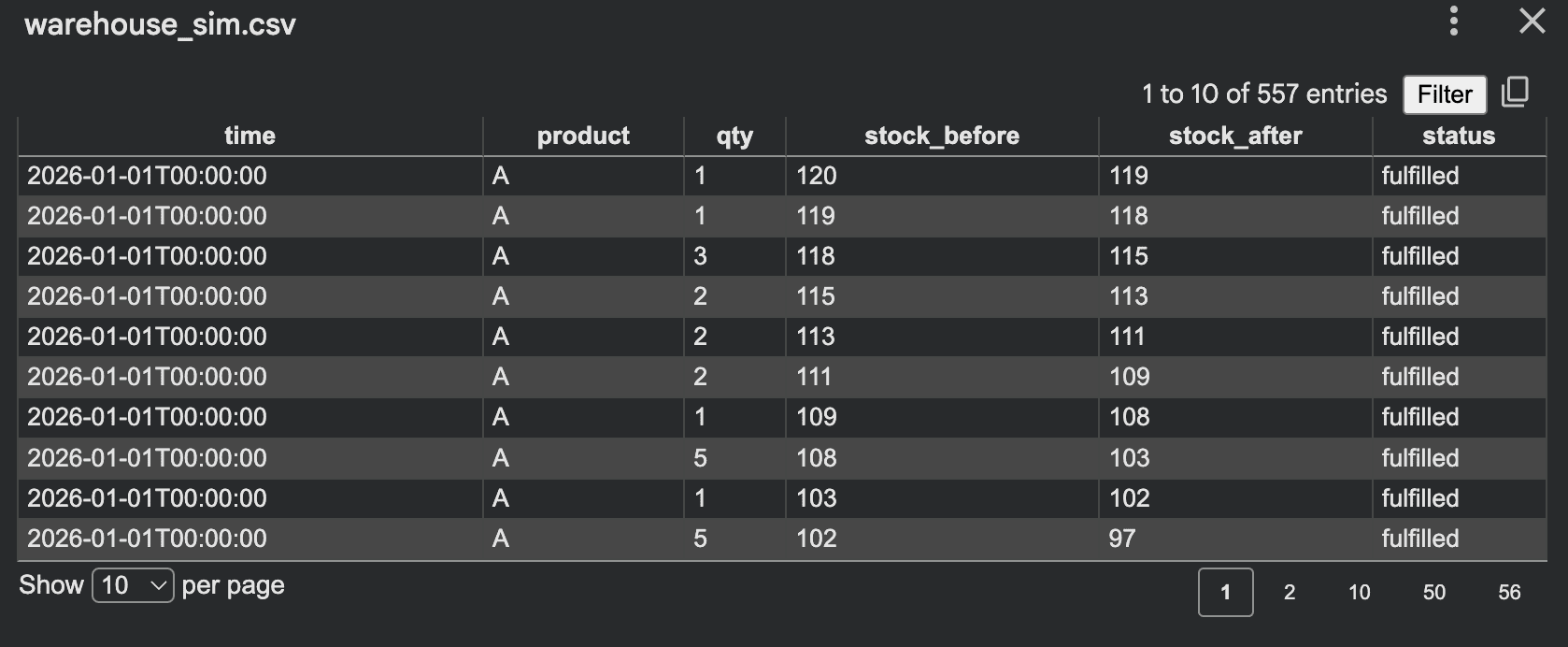
Many real-world systems produce sequential data over time, known as time series. This includes app traffic, sensor readings, financial market movements, or server response times. Generating realistic synthetic time series data requires incorporating trends, seasonality, and noise.
A script for hourly website visits can demonstrate this, incorporating weekday/weekend patterns and daily peaks:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
start = datetime(2026, 1, 1, 0, 0, 0)
hours = 24 * 30 # Simulate 30 days of hourly data
rows = []
for i in range(hours):
ts = start + timedelta(hours=i)
weekday = ts.weekday() # Monday is 0, Sunday is 6
base = 120 # Base visits for weekdays
if weekday >= 5: # Weekend (Saturday or Sunday)
base = 80 # Lower base for weekends
hour = ts.hour
if 8 <= hour <= 11: # Morning peak
base += 60
elif 18 <= hour <= 21: # Evening peak
base += 40
elif 0 <= hour <= 5: # Night slump
base -= 30
# Introduce Gaussian noise for realism, ensuring visits don't go below zero
visits = max(0, int(random.gauss(base, 15)))
rows.append(
"timestamp": ts.isoformat(),
"visits": visits
)
# Code to write to CSV (as in original article)This script generates a time series that exhibits clear daily and weekly cycles, overlaid with random fluctuations. Such data is invaluable for developing forecasting models, detecting anomalies (e.g., sudden drops in traffic), or testing auto-scaling algorithms for cloud infrastructure. More advanced time series generators can incorporate long-term trends, multiple seasonal components, or event-driven spikes. The interpretability of such scripts makes debugging and fine-tuning patterns straightforward, a significant advantage over complex black-box models.
4. Building Event Logs for Behavioral Analysis
Event logs are another critical form of synthetic data, particularly useful for product analytics, security monitoring, and workflow testing. Unlike traditional tabular data where each row represents an entity, event logs capture individual actions or occurrences, often linked to a specific user or system component, sequenced by time.
Consider generating a log of user activities on an e-commerce platform:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
events = ["signup", "login", "view_page", "add_to_cart", "purchase", "logout"]
rows = []
start = datetime(2026, 1, 1)
for user_id in range(1, 201): # Generate events for 200 users
event_count = random.randint(5, 30) # Each user performs 5-30 events
current_time = start + timedelta(days=random.randint(0, 10)) # User's activity starts within first 10 days
has_logged_in = False # Track state for more realistic sequences
has_added_to_cart = False
for _ in range(event_count):
# Enforce some logical flow: e.g., cannot purchase without adding to cart
possible_events = list(events)
if not has_logged_in:
possible_events = ["signup", "login"] # Force login/signup first
elif not has_added_to_cart:
possible_events = [e for e in possible_events if e != "purchase"] # Cannot purchase without cart
event = random.choice(possible_events)
if event == "login":
has_logged_in = True
if event == "add_to_cart":
has_added_to_cart = True
if event == "purchase":
has_added_to_cart = False # Cart is cleared after purchase
value = 0.0
if event == "purchase":
# 60% chance of purchase having a value, otherwise maybe an abandoned cart
if random.random() < 0.6:
value = round(random.uniform(10, 300), 2)
else:
event = "abandoned_cart" # New event type for realism
rows.append(
"user_id": f"USERuser_id:04d",
"event_time": current_time.isoformat(),
"event_name": event,
"event_value": value
)
current_time += timedelta(minutes=random.randint(1, 180)) # Events spaced randomly
# Code to write to CSV (as in original article)This script generates event sequences for multiple users, with event timing and values. A key technique here is to make events dependent on earlier actions, such as a purchase logically following a login and an "add to cart" action. This creates more believable and complex user journeys, which are vital for training models that analyze user behavior, predict churn, or identify fraudulent activities. Such data is invaluable for building funnel analysis dashboards, A/B testing user interface changes, or developing real-time anomaly detection systems for security.
5. Generating Synthetic Text Data with Templates
Synthetic data is also highly valuable for Natural Language Processing (NLP) tasks, especially when real, labeled text data is scarce or sensitive. While LLMs excel at generating highly nuanced text, a template-based approach with Python scripts offers a controlled and efficient way to create structured text datasets for specific purposes.
Consider generating support ticket training data for an intent classification model:
import json
import random
random.seed(42)
issues = [
("billing", "I was charged twice for my subscription"),
("login", "I cannot log into my account"),
("shipping", "My order has not arrived yet"),
("refund", "I want to request a refund"),
("technical", "My software keeps crashing"), # Added more diversity
("feature_request", "Can you add a dark mode option?")
]
tones = ["Please help", "This is urgent", "Can you check this", "I need support",
"I am very frustrated", "Could you assist me with this", "I have a problem"] # Added more tones
products = ["premium service", "mobile app", "website", "desktop software"] # Added products for context
records = []
for _ in range(1000): # Generate 1000 tickets
label, base_message = random.choice(issues)
tone = random.choice(tones)
product_context = random.choice(products) if random.random() < 0.7 else "" # 70% chance of product context
# Construct message with more variation
if product_context:
text = f"tone. base_message regarding my product_context."
else:
text = f"tone. base_message."
# Add minor variations
if random.random() < 0.3:
text += " This is causing a lot of inconvenience."
if random.random() < 0.2:
text = text.replace("I", "My") # Simple word replacement for variation
records.append(
"text": text,
"label": label
)
with open("support_tickets.jsonl", "w", encoding="utf-8") as f:
for item in records:
f.write(json.dumps(item) + "n")
print("Saved support_tickets.jsonl")This script combines predefined issue statements, tones, and optional product contexts to generate diverse support ticket texts, each automatically labeled. This method is highly effective for:
- Bootstrapping NLP Models: Quickly generating initial training data for intent classification, sentiment analysis, or entity recognition when real data is scarce.
- Testing Specific Scenarios: Creating data that targets particular edge cases or rare phrases to improve model robustness.
- Multilingual Data Generation: Adapting templates for different languages to train multilingual models.
- Augmenting Small Datasets: Expanding existing datasets with synthetically generated examples to improve model generalization.
While template-based text may lack the organic nuance of human-generated content, its controlled nature ensures that the generated text adheres to specific linguistic patterns and semantic labels, making it highly valuable for targeted NLP development.
Strategic Advantages and Broader Implications
The ability to generate high-quality synthetic data using Python scripts offers profound strategic advantages across various domains. It democratizes access to data for smaller organizations, startups, and academic researchers who might otherwise be constrained by the lack of proprietary or expensive real datasets. This accelerated data availability speeds up prototyping, allows for more agile experimentation, and fosters innovation in AI development. In educational settings, synthetic datasets provide safe and comprehensible examples for students to learn data science, machine learning, and programming without encountering privacy risks or complex data governance issues. Furthermore, carefully designed synthetic data can be instrumental in addressing algorithmic bias. By generating balanced datasets that correct for underrepresentation or overrepresentation found in real data, developers can actively work towards building fairer and more equitable AI systems, though this requires meticulous design to avoid inadvertently introducing new biases.
Navigating the Pitfalls: Challenges and Ethical Considerations
Despite its immense promise, synthetic data generation is not without its challenges and ethical considerations. Poorly designed scripts can produce data that is either too simplistic, lacking the subtle complexities of real data (low fidelity), or inadvertently replicates biases present in the original data used to inform the generation rules. If the generative model or script is too closely tied to original sensitive data, there’s a risk of privacy leakage, where specific attributes or even entire records of the real data could be inferred from the synthetic output. This underscores the importance of privacy-preserving techniques, such as differentially private synthetic data, which mathematically guarantee that individual records cannot be identified, even when the synthetic data is analyzed.
The quality of synthetic data is paramount; it must accurately reflect the characteristics and relationships of real data to be useful. Developers must guard against common mistakes such as ignoring underlying data distributions, failing to account for correlations between features, or oversimplifying complex temporal patterns. Regular validation against real-world benchmarks, where feasible, is essential to ensure the synthetic data maintains its utility and integrity. Moreover, as real-world data characteristics evolve, synthetic data generation scripts must be continuously updated and refined to remain relevant and accurate.
Conclusion
The capacity to generate diverse, realistic synthetic data using Python scripts is an increasingly indispensable skill for data professionals. From creating simple tabular data with controlled randomness to simulating complex dynamic systems, crafting intricate time series, building detailed event logs, and generating targeted text data, Python offers the flexibility and power to meet a wide array of data needs. This hands-on approach provides not only practical solutions for data privacy, cost reduction, and accelerated AI development but also a deeper, more intuitive understanding of data itself. As the reliance on AI continues to grow and data privacy regulations tighten, the strategic importance of synthetic data will only amplify, solidifying its role as a cornerstone of responsible and innovative data science practices.














Leave a Reply