

The landscape of data acquisition for artificial intelligence (AI) is undergoing a significant transformation, driven by the escalating demand for high-quality, structured content to power large language models (LLMs) and sophisticated AI agents. In this evolving environment, Olostep is positioned as a purpose-built platform designed to simplify the complex process of web crawling, specifically targeting documentation sites and transforming their content into formats readily usable by AI systems. This development marks a pivotal shift from conventional web scraping tools, which often require extensive custom engineering to achieve AI-compatible data outputs.
The Evolving Demands of AI Data Infrastructure
Web crawling, the automated process of traversing web pages and collecting information, has long been a foundational component of internet infrastructure, underpinning search engines, market research, and competitive intelligence. Historically, tools like Scrapy and Selenium have dominated this domain. Scrapy, a powerful and extensible Python framework, offers deep control over the crawling and scraping pipeline, making it suitable for highly customized and large-scale data extraction projects. Selenium, primarily a browser automation tool, excels in interacting with JavaScript-heavy websites and dynamic content, simulating user behavior to access otherwise hidden data.

However, the advent of generative AI and LLMs has introduced a new set of requirements that often challenge the efficiency and direct applicability of these established tools, particularly when dealing with documentation sites. Documentation platforms frequently feature intricate nested structures, recurring navigation elements, boilerplate content, and varied page layouts. The raw output from a standard crawl often includes extraneous interface elements, redundant text, and inconsistent formatting, rendering it suboptimal for direct ingestion by AI models that thrive on clean, coherent, and contextually rich data. The manual effort required to clean, normalize, and structure this data for AI workflows like retrieval-augmented generation (RAG), question-answering systems, or autonomous agents can be substantial, adding significant overhead to development cycles.
Olostep’s Differentiated Approach to Data Preparation
Olostep distinguishes itself by offering a unified API that integrates the entire workflow of search, crawl, scrape, and data structuring. Unlike Scrapy, which demands a more elaborate setup and hands-on engineering for each project, or Selenium, which incurs overhead due to its browser automation focus, Olostep aims for a direct path from URL to AI-ready content. Its core proposition lies in its native support for output formats optimized for LLMs, including Markdown, plain text, HTML, and structured JSON. This eliminates the need for developers to stitch together multiple tools or write extensive post-processing scripts for formatting and cleaning, thereby accelerating the data preparation phase.
For organizations building AI applications that rely on vast repositories of documentation, knowledge bases, or articles, this streamlined approach translates directly into reduced development time and engineering costs. The platform’s design philosophy prioritizes content usability for downstream AI applications, ensuring that extracted data is not just collected but is also immediately valuable for training, fine-tuning, or real-time inference.
Operationalizing an AI-Ready Crawling Pipeline
Implementing an Olostep-powered crawling solution typically begins with a straightforward setup process. Users install the necessary Python packages, including the official Olostep SDK, python-dotenv for secure credential management, and tqdm for progress visualization. The requirement for Python 3.11 or later underscores the platform’s commitment to modern development environments and leveraging recent language features.
The crucial first step involves obtaining an API key from the Olostep dashboard, which is then securely stored in a .env file, adhering to best practices for managing sensitive credentials. This separation of configuration from code enhances security and maintainability, particularly in collaborative development settings.
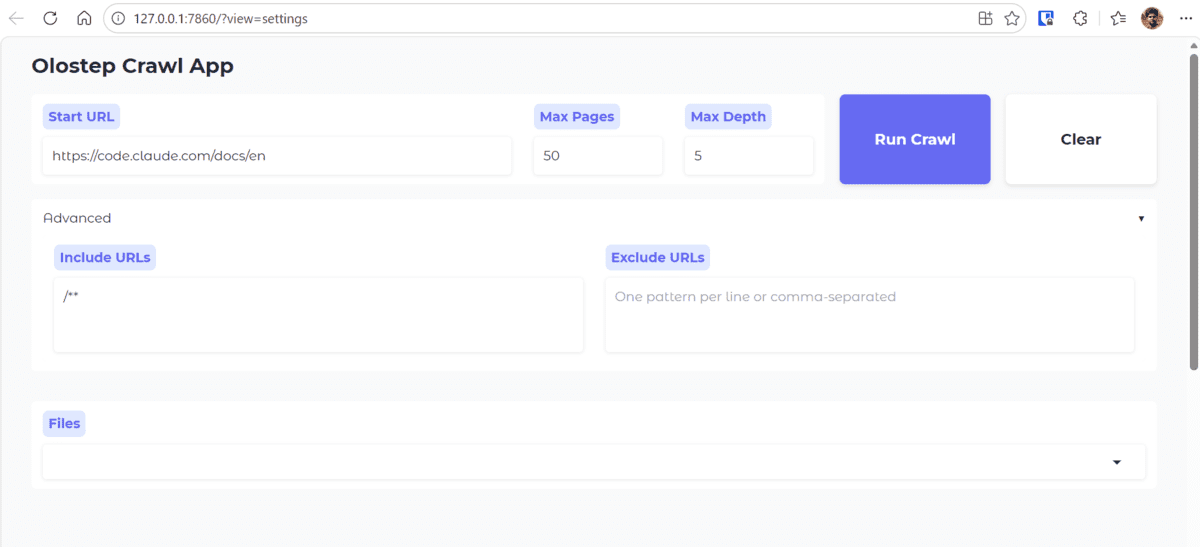
A fundamental component of the solution is the Python crawler script, designed to automate the extraction, cleaning, and local storage of documentation content. The script defines key crawl parameters such as the START_URL, MAX_PAGES, MAX_DEPTH, and rules for including or excluding specific URLs, allowing for precise control over the scope of the crawl. The OUTPUT_DIR specifies where the cleaned Markdown files will be saved.

Central to Olostep’s utility are its intelligent helper functions that address common challenges in web data preparation. A slugify_url function converts complex URLs into filesystem-safe filenames, preventing issues with special characters and directory structures. More critically, the clean_markdown function performs sophisticated post-extraction processing. This function automatically identifies and removes boilerplate content, such as "Copy page" buttons, feedback prompts like "Was this page helpful?", and other interface elements that would pollute AI training data. It also standardizes line breaks and removes superfluous blank lines, ensuring the output is concise and focused purely on the substantive documentation. Finally, a save_markdown function stores the cleaned content, along with its original source URL, in a structured format ready for AI ingestion.
The main crawler logic orchestrates these components. After loading the API key and initializing the Olostep client, it initiates a crawl with the defined parameters. The crawl.wait_till_done() method ensures synchronous processing, and once complete, the script iterates through the crawled pages, retrieves their Markdown content, applies the cleaning function, and saves them locally. This systematic approach ensures that the output directory contains only high-quality, AI-ready documentation. For developers, this means significantly less time spent on data engineering and more time focusing on model development and application logic.
Performance Benchmarks and Economic Implications
One of the compelling aspects highlighted by Olostep’s proponents is its efficiency. A typical crawl of 50 pages with a depth of 5 can be completed in approximately 50 seconds. This rapid processing capability is critical for applications requiring frequent updates to their knowledge bases or for ingesting large volumes of new documentation. In an era where data freshness can significantly impact the performance and relevance of AI systems, such speed provides a distinct competitive advantage.
Beyond raw performance, the economic implications of using a specialized tool like Olostep are substantial. Building and maintaining an internal web crawling solution, especially one capable of handling the complexities of modern documentation sites and delivering AI-ready output, involves significant engineering investment in terms of development, infrastructure, and ongoing maintenance. This includes managing proxies, handling anti-scraping measures, adapting to website changes, and developing robust data cleaning pipelines. Olostep’s commercial model, which often boasts a lower cost per request compared to self-hosted solutions or other market alternatives, makes it an attractive proposition for businesses. As usage scales, the unit economics further improve, positioning it as a practical choice for companies with expanding data infrastructure needs. Industry analysts frequently point to total cost of ownership (TCO) as a critical factor in tool selection, and Olostep’s model appears designed to address this by externalizing much of the operational burden.
Democratizing Access with User-Friendly Interfaces
To further enhance accessibility and usability, the integration of a frontend interface, such as one built with Gradio, represents a strategic move. A Gradio-based web application allows users, even those without deep programming expertise, to interact with the crawler script. Through a simple graphical user interface, individuals can input a target URL, adjust crawl parameters (e.g., maximum pages, depth), initiate the crawl, and then preview the extracted and cleaned Markdown files directly within the browser.
This frontend abstraction serves several vital purposes. It democratizes access to powerful web crawling capabilities, enabling content managers, researchers, or product teams to independently acquire and review documentation. It also facilitates rapid prototyping and iterative testing of crawl settings, allowing users to quickly experiment with different parameters and observe their impact on the output. Furthermore, for sharing the crawling solution within an organization, a user-friendly interface significantly lowers the barrier to adoption, transforming a complex technical script into an accessible business tool. The ability to instantly preview properly formatted Markdown content within the application streamlines the validation process, ensuring the data meets quality standards before being fed into AI systems.
Broader Implications and Future Outlook
The emergence of tools like Olostep signifies a broader trend in data engineering: the move towards specialized, AI-centric solutions that abstract away the complexities of data acquisition and preparation. This shift allows organizations to focus their engineering talent on core AI model development and application logic, rather than on undifferentiated heavy lifting associated with data pipelines.
The implications extend beyond mere cost savings. By providing clean, structured data rapidly and reliably, Olostep contributes to faster iteration cycles for AI development. For instance, in the domain of customer support, continuously updated documentation can feed RAG systems, ensuring that AI-powered chatbots and virtual assistants provide accurate and current information. In enterprise knowledge management, the ability to quickly ingest and process internal documentation facilitates the creation of powerful internal search engines and knowledge graphs.
Looking ahead, the demand for continuous data synchronization will only grow. The capacity to schedule crawls and update only changed pages efficiently, using minimal computational resources, will be paramount. This proactive approach ensures that AI models are always working with the freshest possible information, maintaining their relevance and performance over time.

As the AI industry matures, the reliability, scalability, and strong unit economics offered by specialized data infrastructure platforms will become increasingly vital. The success stories of "fastest-growing AI-native startups" relying on such tools underscore their foundational role in building robust and competitive AI solutions. Olostep’s position within this ecosystem suggests a future where the friction of data acquisition is significantly reduced, empowering more organizations to harness the full potential of AI.














Leave a Reply