
The era of prohibitive costs for developing production-ready, AI-powered applications has concluded, heralding a new paradigm where developers can design, deploy, and scale sophisticated full-stack solutions using exclusively free tools, including the advanced large language models (LLMs) that drive their intelligence. This significant shift, projected to be mainstream by 2026, marks a profound democratization of AI development, making cutting-edge technology accessible to individual creators, startups, and educational institutions without financial burden. The rapid evolution of open-source models, the proliferation of free AI coding assistants, and the availability of robust local deployment options have collectively dismantled traditional barriers to entry, enabling unprecedented innovation.
The Paradigm Shift: From Proprietary to Public
Just a few years ago, the landscape of artificial intelligence development was largely dominated by proprietary solutions, requiring substantial investment in cloud computing resources, expensive API keys from commercial providers, and specialized engineering teams. This created a high barrier for entry, limiting advanced AI application development to well-funded corporations and research institutions. However, a confluence of technological advancements and community-driven initiatives has irrevocably altered this dynamic.
The performance gap between commercial and open-source LLMs has dramatically narrowed, with many open-source alternatives now achieving or even surpassing the capabilities of their proprietary counterparts in specific domains. This is largely attributable to extensive research, collaborative development, and the increasing availability of computational resources for training and fine-tuning these models within the open-source community. Furthermore, the development ecosystem has matured, offering free AI coding assistants that have evolved from basic autocomplete functions to sophisticated agents capable of architecting entire features, significantly accelerating development cycles. Crucially, the ability to run state-of-the-art models locally on standard hardware or leverage generous free tiers offered by cloud providers has eliminated the recurring operational costs that once deterred many aspiring developers.
Unpacking the Economic and Technological Drivers
This transformation is underpinned by several key factors. Economically, the move towards open-source and free-tier offerings is a response to the growing demand for AI capabilities across all sectors, coupled with a desire to mitigate the escalating costs associated with large-scale commercial deployments. For startups and individual developers, the ability to prototype and launch applications without an initial capital outlay is a game-changer, fostering a more vibrant and diverse innovation ecosystem.
Technologically, advancements in model efficiency, quantization techniques, and hardware optimization have made it possible to run powerful LLMs on consumer-grade hardware, often with acceptable latency for many applications. Projects like Ollama and LM Studio exemplify this trend, allowing developers to host and interact with a variety of LLMs directly on their machines. This "self-hosted movement" is not merely about cost savings; it also addresses critical concerns around data privacy, reducing reliance on third-party cloud providers and giving developers full control over their data pipelines.
Another significant development is the widespread adoption of the "Bring Your Own Key" (BYOK) model. This approach empowers developers to utilize free, open-source applications while integrating them with their preferred API providers, including those offering substantial free tiers like Google’s Gemini API, which provides hundreds of free requests daily. This flexibility ensures that developers can select the best-performing model for their specific use case without being locked into a single vendor or incurring immediate costs.
A Practical Demonstration: The AI Meeting Notes Summarizer
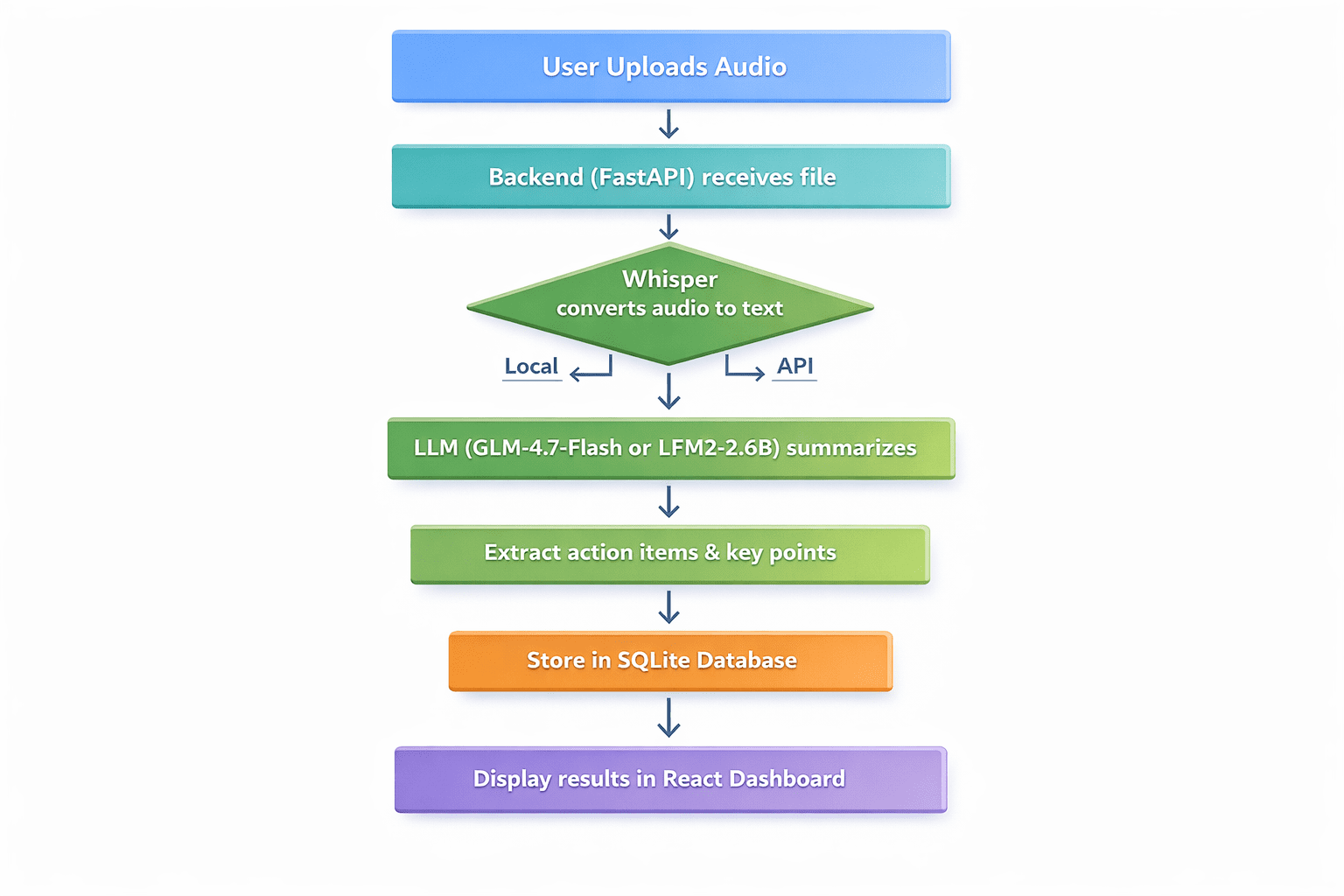
To illustrate the tangible possibilities of this zero-budget approach, a comprehensive tutorial outlines the construction of a real-world application: an AI meeting notes summarizer. This application is designed to receive voice recordings, transcribe them into text, extract key discussion points and actionable items, and present this information within a clean, user-friendly dashboard. Every component, from transcription to summarization and deployment, leverages entirely free tools and services.
The workflow of the application involves several sequential steps:
- Audio Upload: Users upload an audio file containing meeting recordings.
- Transcription: The audio is converted into text using a speech-to-text model.
- Summarization & Analysis: An LLM processes the transcript to identify key points and action items.
- Data Storage: The original audio file (or its metadata), transcript, summary, and action items are stored in a database.
- Display: The summarized information is presented in a web interface.
- User Interaction: Users can view, search, and manage their summarized meetings.
This project serves as a robust blueprint for students, bootcamp graduates, and experienced developers seeking to rapidly prototype and validate ideas without financial risk.
Choosing the Right Free Artificial Intelligence Stack
The selection of tools is critical to achieving a truly zero-budget application while maintaining performance and usability. For the meeting summarizer, a carefully curated stack of free resources is chosen across various layers:

Transcription Layers: Speech-to-Text
Accurate transcription is the foundational step. Several excellent free speech-to-text (STT) tools are available:
- OpenAI Whisper: An open-source model renowned for its high accuracy and support for over 100 languages. It can be self-hosted, offering unlimited usage without cost.
- Whisper.cpp: A privacy-focused C++ implementation of Whisper, ideal for scenarios where data sensitivity is paramount, running entirely on-device.
- Gemini API: Google’s cloud API provides a generous free tier (e.g., 60 requests per minute) for quick prototyping and cloud-based transcription.
For the meeting summarizer, OpenAI Whisper is the recommended choice due to its superior accuracy and flexibility, particularly when self-hosted for local processing.
Summarization and Analysis: The Large Language Model
This is the core intelligence component, and the choices for free LLMs are abundant and increasingly powerful:
- GLM-4.7-Flash (Zhipu AI): A cloud-based model available via a free API, offering general-purpose capabilities and strong performance in coding tasks.
- LFM2-2.6B-Transcript (Liquid AI): Specifically designed and trained for meeting summarization, this model is optimized for local/on-device deployment, running efficiently with minimal RAM (under 3GB). Its specialized nature makes it highly effective for the target application.
- Gemini 1.5 Flash (Google): A cloud API model known for its long context window and a robust free tier, suitable for processing lengthy transcripts.
- GPT-OSS Swallow (Tokyo Tech): A local/self-hosted option, particularly strong in Japanese and English reasoning, showcasing regional contributions to open-source AI.
For the meeting summarizer, LFM2-2.6B-Transcript is highlighted for its specific training data and efficiency, making it an ideal choice for on-device summarization.
Accelerating Development: Artificial Intelligence Coding Assistants
Efficient development is crucial, and free AI coding assistants significantly streamline the process within an Integrated Development Environment (IDE):
- Comate: A VS Code extension offering SPEC-driven, multi-agent capabilities for complex code generation.
- Codeium: Provides unlimited free usage as an IDE extension, supporting over 70 languages with fast inference, making it highly suitable for rapid development.
- Cline: A VS Code extension that supports autonomous file editing, operating on a BYOK model.
- Continue: A fully open-source IDE extension designed to work with any LLM, offering unparalleled flexibility.
- bolt.diy: A self-hosted browser IDE focused on full-stack generation.
Codeium is recommended for its unlimited free tier and speed, with Continue serving as a valuable backup for switching between different LLM providers as needed.
The Development Journey: Backend, LLM Integration, and Frontend
The practical implementation involves setting up the backend, integrating the chosen LLM, and creating a user-friendly frontend.
Setting Up the Backend with FastAPI
The backend is built using FastAPI, a modern, fast (high-performance) web framework for building APIs with Python 3.7+. It offers excellent developer experience, automatic interactive API documentation, and asynchronous capabilities. The process begins with creating a project directory, setting up a virtual environment, and installing necessary packages like fastapi, uvicorn, python-multipart, openai-whisper, transformers, torch, and openai. A main.py file defines the FastAPI application, including CORS middleware for frontend communication, initialization of the Whisper model for transcription, and SQLite for local data storage. The core API endpoint handles audio file uploads, transcribes them using Whisper, and then calls a placeholder function for LLM summarization before saving results to the database.
Integrating the Free Large Language Model
The summarize_with_llm() function is where the intelligence of the application resides. Two primary approaches are presented:
- Cloud-Based (GLM-4.7-Flash API): This option utilizes Zhipu AI’s GLM-4-flash model via its free API. The
openailibrary (compatible with various OpenAI-like APIs) is used to send the transcript to the model with a system prompt instructing it to summarize and extract action items in JSON format. This approach offers simplicity and offloads computation to the cloud. - Local/On-Device (LFM2-2.6B-Transcript): For complete autonomy and privacy, the
LFM2-2.6B-Transcriptmodel from Liquid AI is integrated using thetransformerslibrary. This involves loading the model and tokenizer, preparing a prompt with the transcript, and generating the summary and action items locally using the device’s GPU (if available) or CPU. This method leverages the efficiency of specialized, locally runnable models.
The choice between cloud and local integration depends on specific project requirements for privacy, performance, and resource availability.
Creating the React Frontend
A simple, intuitive React frontend is developed to interact with the FastAPI backend. Using create-react-app, a standard React project is scaffolded, and axios is installed for making HTTP requests. The App.js component manages state for file uploads, processing status, results, and errors. It features an input field for selecting audio files and a button to trigger the analysis. Upon successful processing, the summary and action items are displayed, providing a clear user interface for the application’s core functionality.
Deploying the Application for Free
Bringing the local application to a global audience without incurring costs is the final, crucial step.
Deploying the Backend on Render
Render offers a generous free tier for web services, making it an excellent choice for deploying the FastAPI backend. The deployment process typically involves pushing the code to a GitHub repository, creating a new Web Service on Render, and configuring the build and start commands. A requirements.txt file listing all Python dependencies (fastapi, uvicorn, python-multipart, openai-whisper, transformers, torch, openai) ensures Render can set up the environment correctly. A key consideration for free tiers is disk space and compute limits; models like Whisper and Transformers can be resource-intensive. Developers might need to opt for cloud APIs for transcription if local model sizes exceed free tier limits.
Deploying the Frontend on Vercel
For the React frontend, Vercel stands out as an incredibly user-friendly platform for deploying front-end applications. Similar to Render, deployment involves pushing the React project to a GitHub repository and importing it into Vercel. Vercel automatically detects the framework and configures the build process, making deployment seamless and free for personal and hobby projects.
Exploring Local Deployment Alternatives
For those who prefer to maintain complete control and avoid cloud hosting entirely, local deployment alternatives exist. Tools like ngrok can temporarily expose a local server to the internet, allowing external access to the application without a full cloud deployment. This is useful for demonstrations, testing with external users, or when privacy policies necessitate keeping data strictly within a controlled environment.
Broader Implications and Industry Impact
The democratization of AI development through free and open-source tools carries profound implications for the technology industry and beyond.
Firstly, it significantly lowers the barrier to entry for innovators. Aspiring entrepreneurs, students, and researchers can now experiment with advanced AI concepts without the daunting financial investment previously required. This fosters a more diverse and inclusive ecosystem, potentially leading to breakthroughs from unexpected corners.
Secondly, it promotes greater transparency and auditability in AI. Open-source models allow for scrutiny of their internal workings, which is critical for identifying biases, ensuring fairness, and building trust in AI systems. This stands in contrast to opaque proprietary models, where internal mechanisms are often closely guarded.
Thirdly, the focus on local and on-device AI addresses growing concerns about data privacy and security. By processing sensitive data locally, organizations and individuals can minimize the risks associated with transmitting information to third-party cloud services, adhering to stricter data governance regulations like GDPR.
Finally, this trend accelerates the pace of innovation. The open-source community’s collaborative nature means that improvements and new functionalities are often developed and shared rapidly, creating a virtuous cycle of advancement. As more developers contribute to and build upon these free tools, the capabilities of accessible AI will only continue to expand.
Conclusion
The journey from concept to a production-ready AI application, leveraging exclusively free tools, is no longer a futuristic vision but a present-day reality. This article has detailed the practical construction of an AI meeting notes summarizer, demonstrating how to harness free speech-to-text models like Whisper, powerful LLMs such as GLM-4.7-Flash or LFM2-2.6B-Transcript, and efficient development tools like Codeium, all integrated within a robust FastAPI backend and a responsive React frontend. Furthermore, strategies for free deployment on platforms like Render and Vercel were outlined, completing the full development lifecycle without incurring costs.
The landscape for free AI development has never been more promising. The convergence of increasingly capable open-source models, the enhanced privacy and control offered by local AI tools, and the generous free tiers from leading providers has created an unprecedented opportunity for innovation. This shift empowers a new generation of developers to bring their AI-powered ideas to life, democratizing access to cutting-edge technology and fostering a more vibrant, inclusive, and cost-effective future for artificial intelligence.














Leave a Reply