

The escalating demand for high-quality, structured data to fuel advanced Artificial Intelligence (AI) models, particularly Large Language Models (LLMs), has brought the critical process of web crawling into sharp focus. While traditional web scraping frameworks like Scrapy and browser automation tools such as Selenium have long served developers, their complexity and resource intensity often pose significant challenges when the objective is to systematically acquire and prepare vast quantities of documentation for AI consumption. A novel approach leveraging Olostep, a specialized API-driven platform, is demonstrating a significantly streamlined pathway from raw web content to AI-ready formats, marking a substantial advancement in data acquisition for intelligent systems.
The Evolving Landscape of Web Data for AI
Web crawling, fundamentally the automated process of traversing web pages, following links, and collecting content, is indispensable for constructing comprehensive datasets. From knowledge bases and academic articles to product documentation and news archives, the internet is an unparalleled repository of information. However, transforming this raw, heterogeneous web content into a usable format for AI agents presents a multifaceted challenge. Documentation sites, for instance, are notoriously complex, featuring deeply nested structures, dynamic content, repetitive navigation elements, and significant amounts of boilerplate text that obscure the core information. The process of extracting relevant data, cleaning it, structuring it, and then delivering it in an LLM-friendly format like Markdown or JSON, is far from trivial. This necessitates not just robust crawling capabilities but also sophisticated post-processing to ensure data integrity and utility for downstream AI workflows such as retrieval-augmented generation (RAG), question-answering systems, and autonomous AI agents. The conventional toolset, while powerful, often requires extensive engineering effort, prolonging development cycles and increasing operational costs.

Strategic Shift: Olostep’s API-First Approach
In response to these burgeoning demands, a strategic shift towards API-first solutions is gaining traction. Olostep distinguishes itself from traditional frameworks by consolidating the entire web data pipeline—discovery, crawling, scraping, and structuring—into a unified application programming interface (API). This integrated approach bypasses the need for developers to manually stitch together disparate tools for each stage of data preparation. Unlike Scrapy, which serves as a full-fledged, highly customizable scraping framework demanding considerable setup and boilerplate code, or Selenium, primarily designed for browser automation and interaction with JavaScript-heavy pages rather than large-scale content extraction, Olostep offers a more direct and efficient alternative.
The core proposition of Olostep lies in its ability to deliver LLM-friendly outputs natively. Supported formats include Markdown, plain text, HTML, and structured JSON, making the extracted content immediately compatible with a wide array of AI models. This inherent capability significantly reduces the post-extraction processing burden, allowing AI engineers and data scientists to focus more on model development and less on data wrangling. For organizations with extensive documentation or knowledge bases, this translates into a substantially faster path from a URL to actionable intelligence, thereby accelerating the deployment of AI-powered applications.
Implementing an Efficient Web Crawling Solution with Olostep
The practical implementation of an Olostep-powered crawling solution involves a systematic, Python-based workflow designed for clarity and maintainability. The initial step requires setting up the development environment, specifically installing the necessary Python packages: olostep, python-dotenv, and tqdm. Notably, the official Olostep Software Development Kit (SDK) mandates Python 3.11 or later, reflecting a commitment to modern Python standards. The python-dotenv package is crucial for securely managing API keys and other sensitive credentials, advocating for best practices in development.
Following package installation, users must obtain an API key from the Olostep dashboard, a standard procedure for accessing cloud-based services. This key is then stored in a .env file within the project directory, ensuring it remains separate from the main codebase—a critical security measure.
Developing the Crawler Script: A Step-by-Step Breakdown
The heart of the solution resides in the Python script, crawl_docs_with_olostep.py, which orchestrates the crawling, extraction, cleaning, and local storage of documentation content. The script begins by defining essential crawl settings:

START_URL: The entry point for the crawler.MAX_PAGES: The maximum number of pages to crawl.MAX_DEPTH: The maximum link depth to follow from theSTART_URL.INCLUDE_URLSandEXCLUDE_URLS: Patterns to control which URLs are processed or ignored, providing fine-grained control over the scope of the crawl.OUTPUT_DIR: The local directory where the processed Markdown files will be saved.
A key challenge in saving web content locally is converting URLs into filesystem-safe filenames. To address this, a slugify_url helper function is implemented. This function parses a given URL, extracts its path, and then sanitizes it by replacing problematic characters (like slashes and symbols) with hyphens or underscores, ensuring compatibility across different operating systems. For root paths, it intelligently defaults to "index.md."
Crucially, raw web content often contains superfluous elements—navigation menus, advertisements, feedback prompts, or repeated blank lines—that detract from the core informational value for AI models. The clean_markdown function is designed to meticulously remove these artifacts. It employs regular expressions and string manipulation techniques to:
- Standardize line endings.
- Eliminate empty links.
- Identify and trim introductory boilerplate or trailing feedback sections.
- Consolidate multiple blank lines into single ones.
- Remove specific interface texts that are irrelevant to content understanding.
This rigorous cleaning process ensures that the AI models receive only pertinent, high-quality information, thereby enhancing their performance and reducing computational overhead.
The cleaned Markdown content is then saved by the save_markdown function. This function creates the output directory if it doesn’t exist, constructs a unique filepath using the slugified URL, and writes the content. Importantly, it prepends a YAML front matter containing the source_url, providing crucial metadata for traceability and context within AI applications. A clear_output_dir function is also included to manage disk space and ensure clean runs by removing previous crawl results.
The main crawl function encapsulates the core logic. It loads the Olostep API key, initializes the Olostep client, and then initiates a crawl request with the predefined settings. The API call includes parameters such as include_external and include_subdomain (both set to False in the example) to restrict the crawl scope to the target domain, and follow_robots_txt (set to True) to respect website policies. Once the crawl is initiated, the script waits for its completion, polling the API periodically. Upon successful completion, it retrieves all crawled pages, iterates through them, extracts their Markdown content, cleans it using the clean_markdown function, and saves it locally. Progress is visually tracked using tqdm, a Python library for progress bars, providing real-time feedback to the user.
Bridging the Gap: A Gradio-Powered Web Application
To enhance accessibility and user-friendliness, the underlying crawler script is wrapped within a simple web application built using Gradio. Gradio is an open-source Python library that allows for the rapid creation of customizable user interfaces for machine learning models and data processing pipelines. This web application transforms the command-line script into an interactive tool where users can input a target URL, define crawl parameters (e.g., maximum pages, depth), initiate the crawl, and then preview the extracted Markdown files directly within a browser interface.
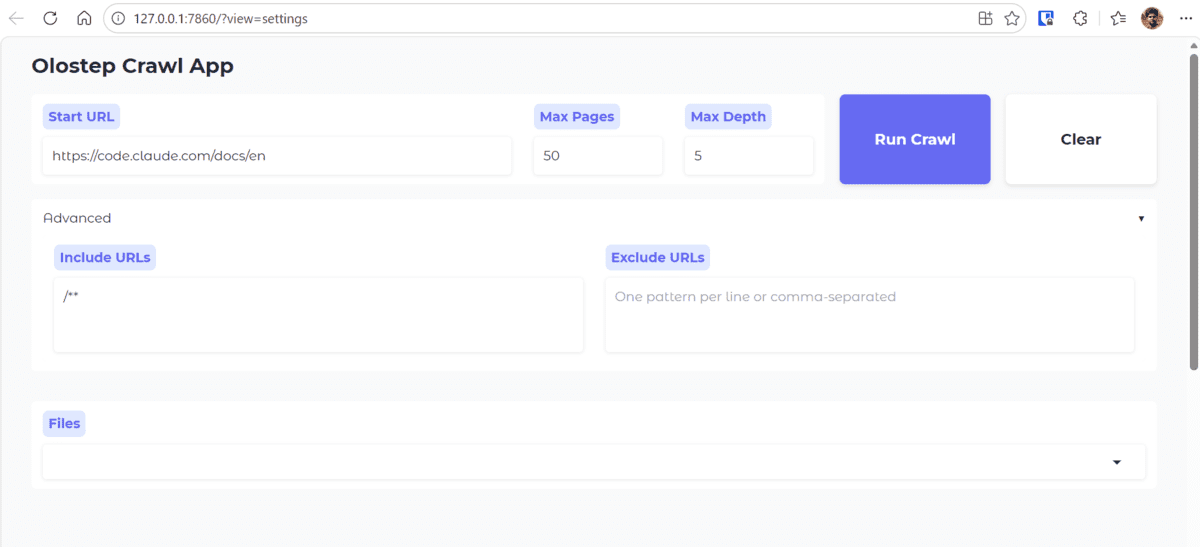
The app.py frontend code, available in the project repository, exposes the crawler’s functionalities through an intuitive graphical interface. When a user submits a URL and settings, the application invokes the backend Python script, passing the parameters dynamically. This abstraction allows non-technical users or those unfamiliar with Python to leverage the powerful crawling capabilities without modifying code. The application’s interface typically includes input fields for the URL, sliders or dropdowns for crawl depth and page limits, and a "Run Crawl" button. Upon completion, it dynamically updates a dropdown menu with the names of the saved Markdown files, enabling users to select and view the content rendered in the browser. This immediate feedback loop is invaluable for verifying extraction quality and iterating on crawl settings. For instance, a demonstration using the Claude Code documentation URL, crawling 50 pages with a depth of 5, showcases the application’s ability to efficiently process and display complex technical content. The typical execution time for such a crawl, approximately 50 seconds, underscores the efficiency gains provided by Olostep compared to traditional methods that might involve hours of setup and execution for similar volumes of data.
Broader Implications and Strategic Advantages
The advent of specialized crawling APIs like Olostep carries significant implications for data engineering, AI development, and competitive business strategies. The traditional hurdles of web data acquisition—ranging from IP blocking and CAPTCHAs to inconsistent website structures and dynamic content rendering—are largely abstracted away, allowing development teams to focus on higher-value tasks.
Cost-Effectiveness and Scalability: Building and maintaining an in-house web crawling solution, especially one capable of handling the scale and complexity required for AI data pipelines, entails substantial investment in infrastructure, developer time, and ongoing maintenance. Olostep offers a compelling alternative by providing a managed service that is "significantly more affordable than building or maintaining an internal crawling solution," with claims of being "at least 50% cheaper than comparable alternatives on the market." This cost advantage, coupled with a decreasing cost-per-request as usage scales, makes it a highly practical choice for both startups and established enterprises looking to optimize their data infrastructure spending.
Agility in AI Development: For AI-native startups and research labs, rapid access to clean, structured, and up-to-date web data is paramount. Olostep’s efficiency means that datasets can be refreshed frequently, ensuring AI models are trained and augmented with the latest information. This agility supports iterative model development, faster deployment of new features, and more responsive AI agents, which is crucial in fast-evolving fields like LLM development. The ability to schedule crawls and update only changed pages further optimizes resource utilization and data freshness.
Enhanced Data Quality for LLMs: The native support for Markdown and structured JSON output directly addresses one of the most critical challenges in LLM development: data quality. LLMs perform optimally with well-structured, clean text. By automatically handling boilerplate removal, content normalization, and metadata inclusion, Olostep significantly elevates the quality of input data, leading to more accurate, relevant, and robust AI model outputs. This is particularly vital for retrieval-augmented generation (RAG) systems, where the precision of retrieved information directly impacts the quality of generated responses.

Competitive Edge: In an increasingly data-driven economy, organizations that can efficiently acquire, process, and leverage web intelligence gain a distinct competitive advantage. Whether it’s for market research, competitive analysis, trend monitoring, or enhancing customer support with AI-powered knowledge bases, streamlined web crawling capabilities enable businesses to make faster, more informed decisions and to develop superior AI products and services. The demonstrated efficiency, where crawling 50 pages with depth 5 takes only around 50 seconds, is indicative of a workflow that supports real-world, time-sensitive applications.
In conclusion, the evolution of web crawling solutions, exemplified by platforms like Olostep, marks a pivotal moment for AI data acquisition. By simplifying the complex process of extracting and structuring web content, it empowers developers and organizations to build more capable, cost-effective, and rapidly deployable AI applications. This shift towards API-driven, purpose-built crawling solutions is not just an incremental improvement but a fundamental change in how enterprises will manage and leverage the vast digital knowledge base for their AI initiatives, underpinning the growth of AI-native technologies.











Leave a Reply