

In a significant stride towards empowering individuals with greater control over their financial data, software engineer Shittu Olumide has developed an AI-powered financial analysis application designed to operate entirely locally, circumventing the prevalent practice of uploading sensitive information to cloud servers. This innovative Python-based tool, detailed in a recent project showcase, addresses a critical gap in personal finance management by offering robust spending analysis, unusual transaction detection, and clear AI-generated insights, all while ensuring 100% data privacy. The initiative reflects a growing demand for privacy-preserving technologies in an era marked by increasing data breaches and concerns over digital security.
The genesis of this project stemmed from a common frustration: the opaque nature and inherent privacy risks associated with existing personal finance applications. Many commercially available tools require users to grant access to or upload their bank statements to third-party servers, where data is processed, stored, and potentially monetized. Olumide’s personal quest for a more secure and transparent solution began when he sought to understand his own spending patterns without compromising his financial privacy. What started as a weekend endeavor rapidly evolved into a comprehensive exploration of real-world data challenges, pragmatic machine learning, and the burgeoning capabilities of local large language models (LLMs). This project not only delivers a functional application but also serves as a practical guide to essential data science concepts applicable across diverse analytical domains.
The Imperative for Local Data Processing
The core problem tackled by Olumide’s application is the fundamental flaw in most personal finance apps: the surrender of data control. Users typically relinquish ownership of their financial records to services that store, process, and potentially leverage this information for various purposes, often with ambiguous privacy policies. The objective for this new tool was clear: to create an analyst that could process data locally, provide immediate insights, offer full transparency into its operations, and be entirely customizable by the user. This approach aligns with a broader societal push for data sovereignty, where individuals maintain complete control over their digital footprint. According to various surveys, data privacy is a top concern for over 80% of internet users, a sentiment that resonates particularly strongly when it comes to financial information. The financial services industry, in particular, is a frequent target of cyberattacks, with reports indicating millions of records compromised annually, further fueling the need for local, secure solutions.

Architectural Foundations: Building a Robust System
The application’s architecture is thoughtfully segmented to ensure modularity, efficiency, and maintainability. At its heart lies app.py, the main Streamlit application that provides the user interface. Complementing this are dedicated modules for config.py (handling settings like categories and LLM configurations), preprocessing.py (for automated CSV format detection and data normalization), ml_models.py (housing the transaction classifier and anomaly detector), visualizations.py (for interactive Plotly charts), and llm_integration.py (managing the local LLM interaction). This structured approach underscores best practices in software development and data science, allowing for independent development and easier debugging of each component.
Step 1: Mastering Real-World Data Preprocessing
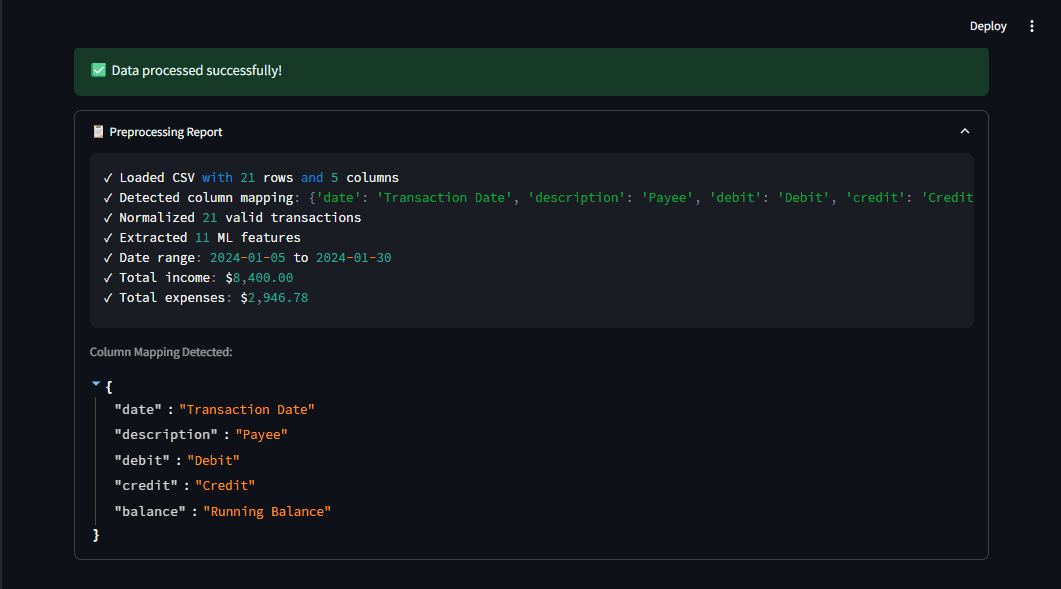
One of the project’s initial and most critical challenges was the inherent messiness of real-world financial data. Bank statements from different institutions—be it Chase, Bank of America, Moniepoint, or OPay—rarely adhere to a standardized format. Column names vary wildly (e.g., "Transaction Date," "Date," "Posting Date"; "Amount," "Transaction Amount"; "Debit," "Withdrawal," "Expense"). To overcome this, Olumide engineered a robust preprocessing pipeline capable of automatically detecting column mappings using a pattern-matching system based on regular expressions. This intelligent system identifies common financial fields regardless of their specific nomenclature, translating them into a unified schema.
For instance, the system employs patterns like r"date|trans.*date|posting.*date" for date columns and r"^amount$|transaction.*amount" for amounts. Once identified, the data is normalized into a consistent structure. This is particularly vital for banks that separate debits and credits into distinct columns, which are then intelligently combined into a single ‘amount’ column (negative for expenses, positive for income). This normalization step is paramount; it simplifies all subsequent operations, from feature engineering and machine learning modeling to data visualization, proving that a clean, consistent dataset is the bedrock of any successful data analysis project. The transparency offered by a preprocessing report, which shows detected columns and a data summary, further builds user trust.
Step 2: Pragmatic Machine Learning for Limited Datasets
The second significant hurdle involved the constraint of limited training data. Unlike enterprise-level applications with vast, labeled datasets, a personal finance tool relies on individual users uploading their unique statements, making traditional deep learning approaches impractical. Olumide opted for algorithms that perform effectively with smaller samples and can be augmented with simple, interpretable rules.
For transaction classification, a hybrid approach was employed:
- Rule-based Matching: A set of predefined categories and associated keywords (e.g., "groceries" matching "walmart," "costco"; "dining" matching "restaurant," "starbucks") allows for immediate classification without any training data. This ensures a baseline of functionality from the outset.
- Fine-tuned Machine Learning: For transactions not caught by rules, a simple, lightweight machine learning model (such as a logistic regression or a small support vector machine) could be trained on the user’s growing, manually categorized data, learning from patterns specific to their spending habits. This adaptability allows the system to improve over time with minimal user input.
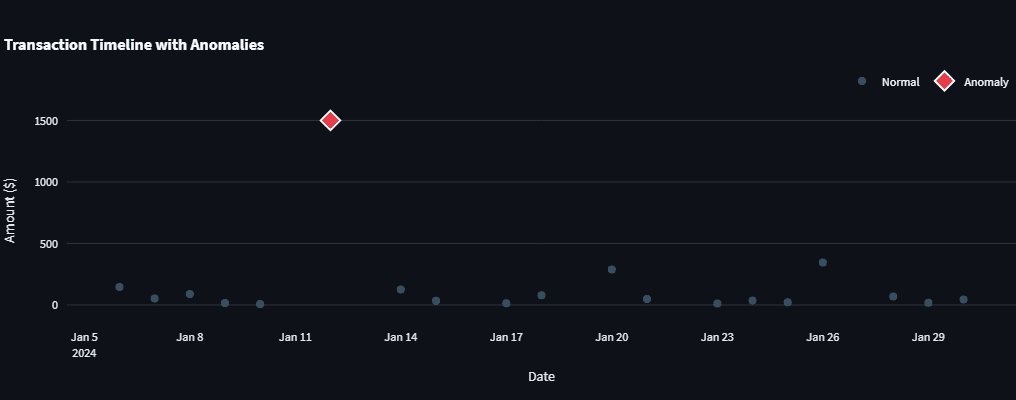
Anomaly detection, crucial for spotting unusual spending or potential fraud, utilizes Isolation Forest from scikit-learn. This algorithm is particularly well-suited for several reasons: it performs well with small datasets, it doesn’t require prior knowledge of data distribution, and it is computationally efficient. Isolation Forest works by randomly partitioning data points, isolating anomalies faster than normal data points due to their unique characteristics. The algorithm’s contamination parameter allows for an estimation of the proportion of anomalies in the dataset (e.g., 5%), guiding its sensitivity. This machine learning approach is further bolstered by simple statistical checks, such as Z-score analysis, to identify outliers that deviate significantly from the mean, providing a multi-layered defense against missed anomalies. This demonstrates a key takeaway for data scientists: often, simple, well-chosen algorithms, especially when combined with heuristic rules, can outperform complex models when data is scarce.
Step 3: Crafting Visualizations for Actionable Insights
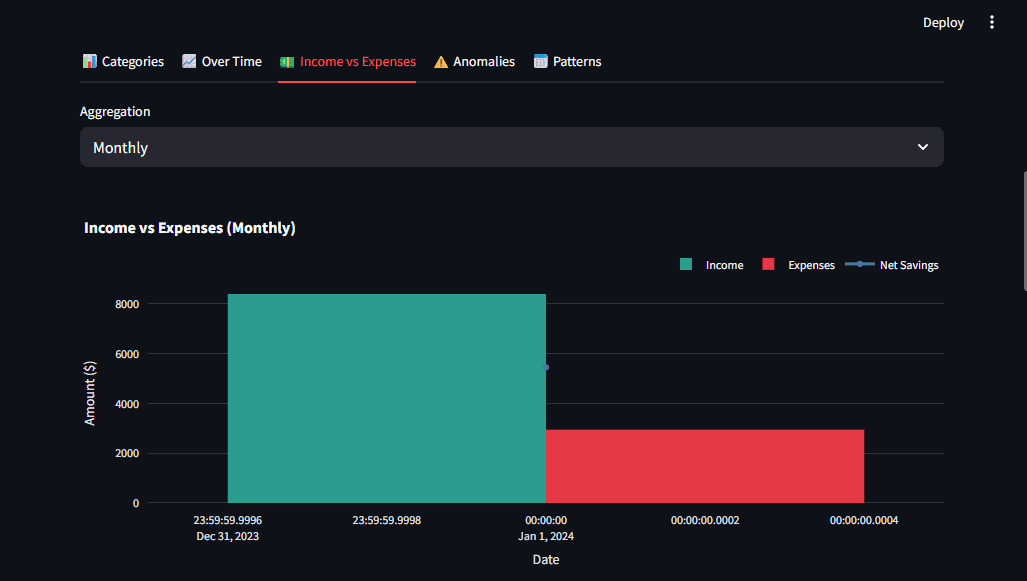
Beyond raw data and classifications, the ability to visualize financial trends is paramount for user understanding and decision-making. Olumide leveraged Plotly, a powerful Python graphing library, to create interactive charts that are not just aesthetically pleasing but also answer specific user questions. The design principles centered on clarity, interactivity, and multiple perspectives. Visualizations were crafted to highlight key metrics immediately, allowing users to drill down into details as needed.
For example, a donut chart provides a clear spending breakdown by category, with a clean central hole for better aesthetics. Bar charts offer comparisons over time or across categories, while timeline charts effectively highlight anomalies or significant events. Heatmaps could be employed for visualizing spending patterns across different days of the week or months. The integration with Streamlit facilitates the creation of a responsive and intuitive dashboard, where users can effortlessly navigate through their financial data. This emphasis on user-centric design transforms raw data into understandable narratives, empowering users to gain insights into their financial health.
Step 4: Local LLM Integration for Natural Language Insights
Perhaps the most compelling feature of the application is its integration with a local Large Language Model (LLM) for generating human-readable financial insights. Instead of relying on cloud-based LLM APIs like OpenAI or Claude, which would necessitate uploading sensitive data, Olumide chose Ollama. Ollama allows users to run LLMs directly on their own hardware, offering several distinct advantages:
- Guaranteed Privacy: Financial data never leaves the user’s machine, eliminating third-party access risks.
- Cost-Effectiveness: No API usage fees, making the tool more accessible and sustainable for long-term use.
- Offline Capability: The application can function even without an internet connection, provided the LLM is downloaded.
To enhance user experience, the LLM integration leverages streaming, meaning responses are displayed token by token as they are generated, making the wait feel significantly shorter. This is achieved using standard HTTP requests to the local Ollama server, with Streamlit’s st.write_stream() function handling the dynamic display.
Effective prompt engineering is crucial for extracting meaningful insights from the LLM. Olumide designed structured prompts that include actual financial summaries—total income, expenses, top spending categories, and descriptions of largest anomalies. This contextual data enables the LLM to generate specific, actionable recommendations, moving beyond generic advice to personalized financial guidance. For instance, a prompt might ask the LLM to "Analyze this financial summary: Total Income: $X, Total Expenses: $Y, Top Category: Z. Provide 2-3 actionable recommendations based on this data." This method ensures the LLM acts as a personalized financial advisor, offering tailored insights based on the user’s unique spending habits.
Running the Application and Broader Implications
Getting started with the application is straightforward, requiring Python, a few dependency installations via pip, and an optional ollama pull llama3.2 command for AI insights. Once launched with streamlit run app.py, users can upload any bank CSV, and the application automatically processes the data, presenting a dashboard with categorized transactions, flagged anomalies, and AI-generated insights within seconds. The complete source code is openly available on GitHub, inviting community contributions and further development.
This project carries significant implications beyond personal finance management. It stands as a powerful testament to the potential of privacy-preserving AI. In an era where data is increasingly viewed as a commodity, Olumide’s work demonstrates that powerful analytical tools can be built without sacrificing personal privacy. It champions the democratization of AI, allowing individuals to leverage sophisticated models without the high costs or data-sharing obligations often associated with cloud-based solutions. Furthermore, it contributes to the burgeoning open-source movement in AI and data science, fostering collaboration and innovation.
For aspiring data scientists, the project offers invaluable practical lessons: the necessity of robust data preprocessing for messy real-world data, the art of choosing pragmatic machine learning models for limited datasets, the importance of designing visualizations that truly answer user questions, and the strategic integration of privacy-aware AI. These principles transcend the domain of personal finance, finding relevance in analyzing sales data, server logs, scientific measurements, and countless other data-intensive fields. Shittu Olumide, a software engineer and technical writer known for simplifying complex technical concepts, has not only built a useful tool but also provided a blueprint for future privacy-centric AI applications. His work encourages others to fork, extend, and innovate upon this foundation, heralding a future where individuals have greater control and understanding of their digital lives.














Leave a Reply