

The recent demonstration of constructing a fully functional vector search engine using only Python’s NumPy library underscores a critical shift in information retrieval, moving beyond archaic keyword matching to embrace semantic understanding. This development, detailed in a technical article, highlights how developers can create powerful search capabilities that grasp the meaning behind queries, not just the exact words. Such an approach addresses a long-standing challenge in digital interaction: the frustrating gap between a user’s typed words and their true intent, a chasm that traditional search algorithms often fail to bridge.
The Semantic Revolution in Information Retrieval
For decades, search engines operated predominantly on keyword matching, relying on the literal presence of words in a document to determine relevance. While effective for highly specific queries, this method frequently faltered when faced with synonyms, nuanced phrasing, or conceptual searches. Users often encountered results that were syntactically correct but semantically irrelevant, leading to suboptimal experiences in e-commerce, content discovery, and data retrieval. The advent of vector search technology, however, has initiated a paradigm shift, enabling systems to interpret the contextual meaning of queries and documents alike.
Vector search achieves this by transforming text into numerical representations known as embeddings. These embeddings are high-dimensional vectors, essentially points in a vast mathematical space, where the geometric proximity between two vectors directly correlates with the semantic similarity of the texts they represent. This means two sentences conveying the same idea, even if they share no common words, will have embeddings that are spatially close. The underlying principle is that "closeness in vector space means semantic similarity," a concept foundational to modern artificial intelligence applications.
The practical demonstration outlined in the technical article showcased how a basic vector search engine could be built from the ground up using fundamental Python libraries like NumPy. This "from scratch" approach demystifies the complex workings of vector search, revealing how embeddings are stored, normalized, and how similarity metrics like cosine similarity are efficiently computed. It provides a clear blueprint for understanding the core mechanics without relying on opaque, high-level libraries, making the technology more accessible to a wider developer audience.
Understanding Vector Search: Beyond Keywords
At the core of vector search is the process of converting unstructured data, such as text, images, or audio, into dense numerical vectors. These vectors, often hundreds or thousands of dimensions long, are generated by sophisticated machine learning models, frequently deep neural networks. For text, models like Google’s BERT, OpenAI’s embedding models, or Sentence-Transformers are commonly used. These models are trained on vast datasets to learn the contextual relationships between words and phrases, projecting them into a continuous vector space where semantically similar items are mapped to nearby points.
The choice of distance metric is crucial for determining "closeness" in this high-dimensional space. While Euclidean distance measures the straight-line distance between two points, cosine similarity is overwhelmingly preferred in semantic search. Cosine similarity calculates the cosine of the angle between two vectors, effectively measuring their directional alignment rather than their absolute separation. This characteristic makes it scale-invariant, meaning that the length (magnitude) of the vector does not influence the similarity score. In practical terms, this is highly beneficial because the "importance" or "length" of a document should not unduly affect its semantic relevance to a query. A short, highly relevant query or document can still be semantically close to a longer, equally relevant document. Normalizing vectors (scaling them to unit length) further simplifies cosine similarity calculations, reducing them to a simple dot product, a computationally efficient operation.
The Python implementation detailed in the article specifically highlighted this efficiency. By normalizing all stored document embeddings and the incoming query vector, the system could leverage NumPy’s optimized matrix multiplication for rapid computation of similarity scores across the entire dataset. This transformation from a potentially costly angle calculation to a direct dot product is a key optimization technique in vector search, particularly for large-scale systems.
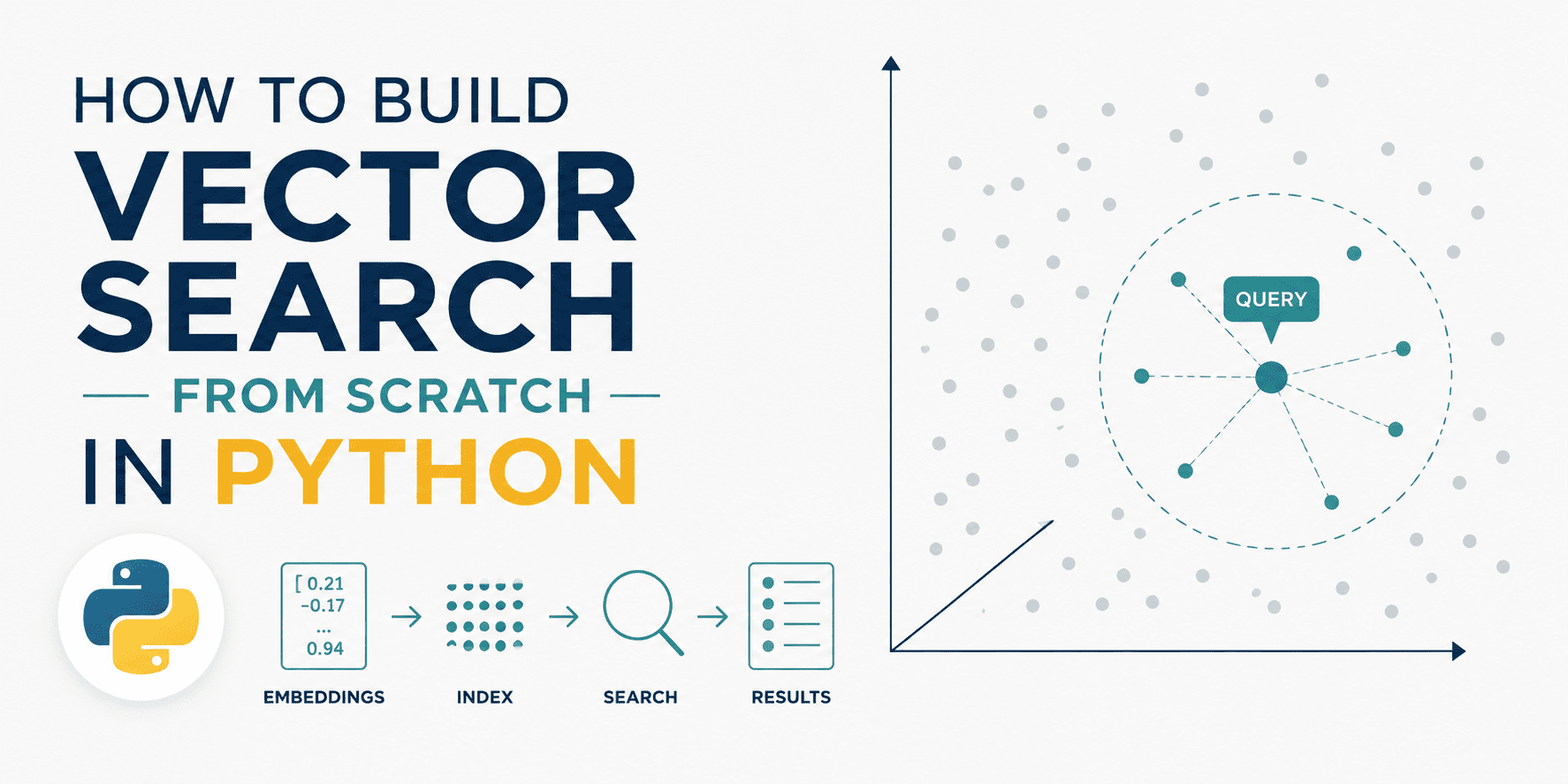
A Brief History of Semantic Search Technologies
The journey to modern vector search is rooted in decades of advancements in natural language processing (NLP) and machine learning. Early attempts at semantic understanding in search involved techniques like Latent Semantic Analysis (LSA) in the late 1980s and Probabilistic Latent Semantic Analysis (pLSA) in the late 1990s, which aimed to uncover latent semantic relationships between words and documents. These methods, while groundbreaking, were computationally intensive and struggled with scalability and capturing nuanced meanings.
The early 2010s marked a significant turning point with the introduction of "word embeddings" like Word2Vec by Google in 2013 and GloVe by Stanford in 2014. These models demonstrated that words could be represented as dense vectors, where mathematical relationships between vectors mirrored semantic relationships between words (e.g., vector(‘king’) – vector(‘man’) + vector(‘woman’) ≈ vector(‘queen’)). This laid the groundwork for representing entire sentences and documents as vectors.
The mid-to-late 2010s saw the rise of deep learning architectures, particularly recurrent neural networks (RNNs) and transformers, which revolutionized NLP. Models like ELMo (Embeddings from Language Models) and BERT (Bidirectional Encoder Representations from Transformers), introduced in 2018, provided "contextual embeddings." Unlike static word embeddings, contextual embeddings generate a vector for a word based on its surrounding words in a sentence, capturing much richer semantic information. This innovation dramatically improved the quality of sentence and document embeddings. Projects like Sentence-Transformers further streamlined the process of generating high-quality sentence embeddings, making the technology more accessible to developers.
Concurrently, the need to efficiently search through billions of these high-dimensional vectors led to the development of specialized "vector databases" and Approximate Nearest Neighbor (ANN) algorithms. Traditional databases are not optimized for vector similarity search. Companies like Pinecone, Milvus, Weaviate, and even established players like Elastic (with its vector search capabilities) emerged, offering scalable infrastructure for storing, indexing, and querying vectors. These systems employ advanced ANN algorithms (e.g., HNSW, IVFFlat) that sacrifice a tiny bit of accuracy for immense speed improvements, making real-time semantic search feasible at internet scale. The NumPy-based implementation, while demonstrating the core math, uses a brute-force search; production systems rely on these ANN algorithms for performance.
The Foundational Principles: NumPy Implementation
The technical article provided a concrete example of how these abstract concepts translate into executable code. It began by setting up a synthetic dataset: a small catalog of 15 fictional product descriptions, pre-embedded as 8-dimensional vectors. While real-world applications would generate these embeddings using pre-trained models like sentence-transformers, the tutorial used controlled random data with distinct cluster centers to clearly illustrate semantic grouping (electronics, clothing, furniture). This simulated environment allowed for a clear demonstration of the core principles without the overhead of model inference.
The crucial component was the VectorIndex class, designed to store and manage these embeddings. Its add method performs a critical step: L2-normalization of all incoming vectors. This normalization ensures that each vector has a unit length, simplifying subsequent cosine similarity calculations. As previously noted, with normalized vectors, cosine similarity elegantly reduces to a simple dot product, a highly optimized operation in numerical computing libraries like NumPy.
The search method within the VectorIndex class encapsulates the entire retrieval process. Upon receiving a query vector, it first normalizes it. Then, it performs a single matrix multiplication (the dot product) between the normalized query vector and the entire matrix of normalized stored embeddings. This operation simultaneously calculates the cosine similarity between the query and every item in the index. The resulting scores are then sorted, and the top-k items are returned. This elegant use of matrix operations underscores the efficiency that makes vector search practical even for large datasets, especially when executed on modern hardware optimized for parallel computations. The code, concise and direct, laid bare the mathematical operations, providing a robust educational tool for understanding the mechanics.
Demonstrating Semantic Retrieval: Query Execution
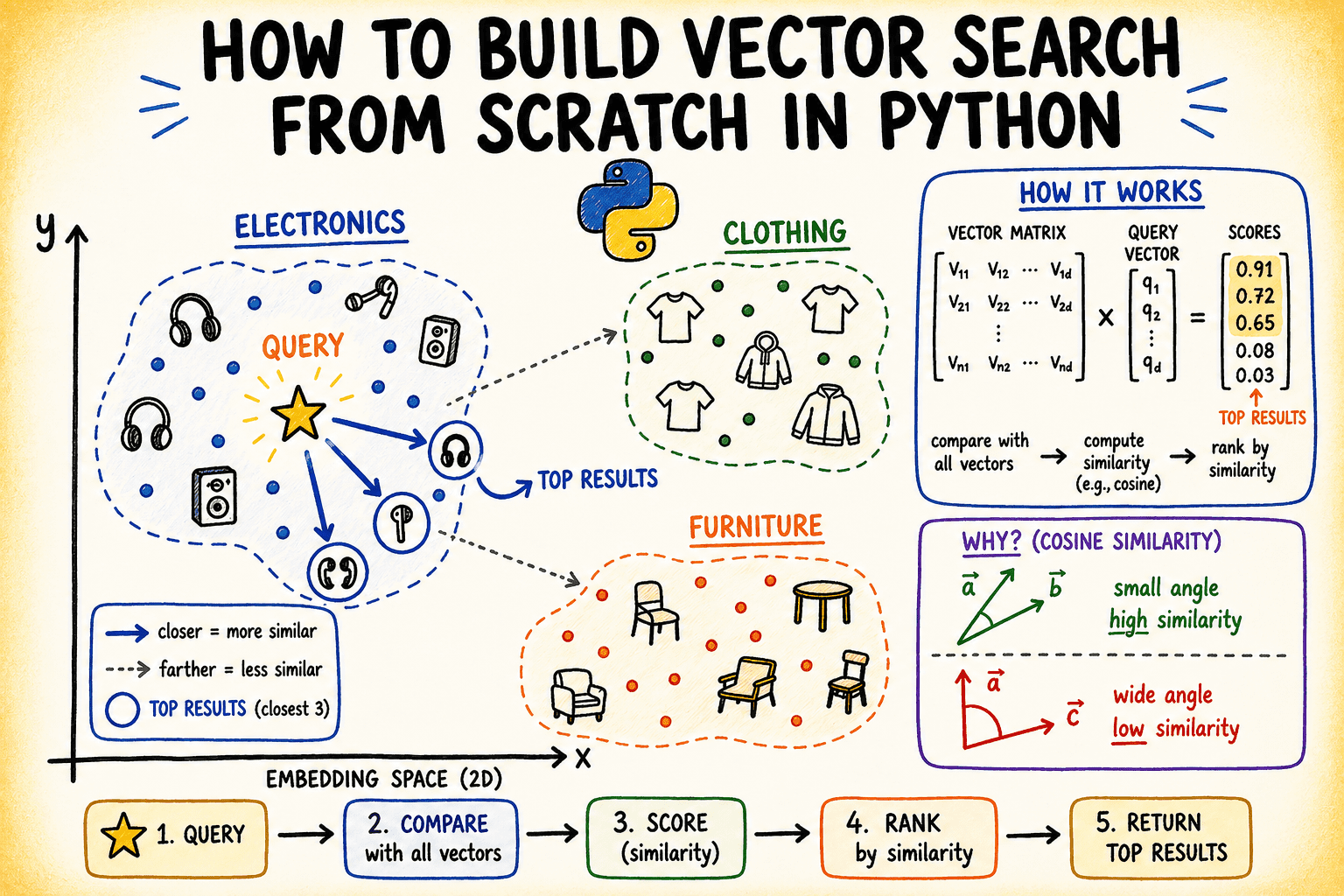
To validate the homegrown vector search engine, the article conducted several queries, simulating real user input. Query vectors were constructed by introducing slight noise to the established cluster centers (e.g., "audio equipment" for the electronics cluster). This mimicked the variability of real-world query embeddings while ensuring a clear semantic target.
The results were strikingly accurate. A query for "audio equipment" consistently returned items like "Wireless noise-cancelling headphones" and "Bluetooth speaker," along with other electronics, all exhibiting high similarity scores close to 1.0. Similarly, "casual wear" retrieved clothing items like "Men’s slim-fit chino pants" and "Women’s merino wool turtleneck sweater," while "home furniture" yielded "Bamboo bookshelf" and "Linen sofa." The high scores (typically above 0.98) indicated a strong semantic match, confirming that the system successfully identified semantically related items even when the query terms themselves might not have been direct keyword matches to the product descriptions. This demonstrated the power of vector search to transcend lexical boundaries and operate on the level of meaning.
Visualizing the High-Dimensional Landscape
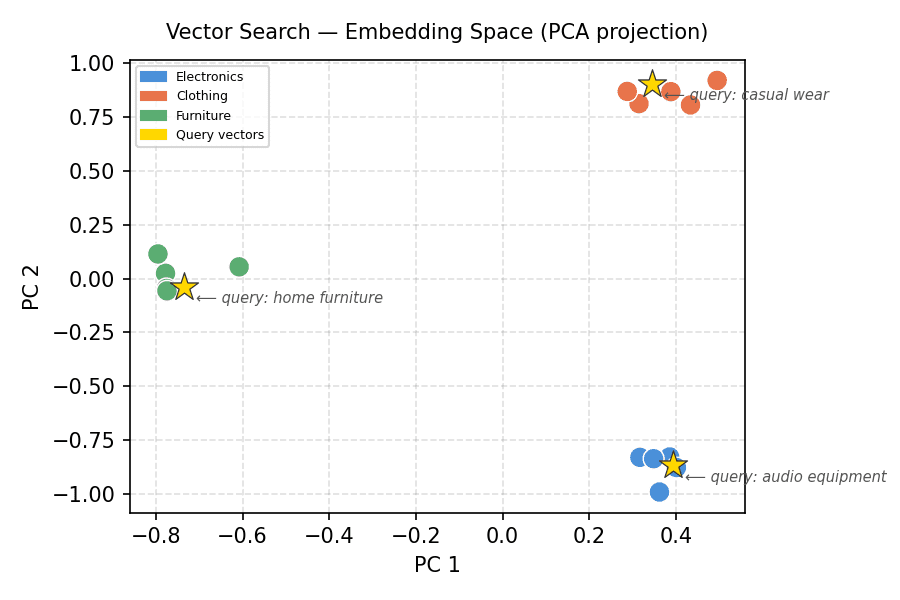
One of the challenges in comprehending vector search is the abstract nature of high-dimensional space. An 8-dimensional vector, let alone one with hundreds of dimensions, cannot be directly visualized. To overcome this, the article employed Principal Component Analysis (PCA), a dimensionality reduction technique. PCA identifies the directions (principal components) along which the data varies the most and projects the high-dimensional data onto a lower-dimensional subspace, typically 2D or 3D, while preserving as much of the original variance as possible.
The 2D PCA projection of the 8-dimensional product embeddings vividly illustrated the underlying semantic structure. The plot clearly showed three distinct clusters, corresponding to electronics, clothing, and furniture. Each cluster was tightly grouped, confirming that the simulated embeddings effectively captured the semantic categories. Crucially, when the query vectors were also projected into this same 2D space, each query (represented by a gold star) landed squarely within its corresponding semantic cluster. The "audio equipment" query appeared within the electronics cluster, "casual wear" within clothing, and "home furniture" within the furniture cluster. This visual confirmation is a powerful testament to how vector search leverages geometric proximity for semantic relevance. It concretely demonstrated that the engine was not just returning arbitrary matches but was indeed operating within a semantically organized space.
Assessing Relevance: Score Distribution Analysis
Beyond merely listing the top-k results, understanding the distribution of similarity scores across the entire index provides valuable diagnostic insights. The article presented a visualization of similarity scores for a specific query ("home furniture") against all products. This horizontal bar chart, ordered by descending similarity, showcased a clear separation: the furniture items consistently ranked at the top with high scores, followed by a noticeable drop-off before other categories appeared.
This "gap" in scores is highly informative. It indicates a strong signal for the relevant cluster and suggests that the top results are not just marginally better than the rest, but represent a clear semantic alignment. In practical applications, this distribution can guide the setting of similarity thresholds. For instance, a system might be configured to only return results with a similarity score above a certain cutoff, effectively filtering out less relevant items and improving the quality of search results presented to the user. This visualization served as a practical tool for evaluating the efficacy of the vector space and the precision of the search mechanism.
Industry Impact and Future Trajectories
The implications of accessible vector search technology, as demonstrated by this NumPy-based implementation, are profound. Vector search is no longer a niche academic concept but a cornerstone of modern AI applications.
In e-commerce, companies like Amazon and Netflix leverage vector search for personalized product recommendations and content discovery, leading to increased user engagement and sales. When a user browses a product, its embedding can be used to find semantically similar items, even if they belong to different categories or have no shared keywords.
For Generative AI, vector search is foundational to Retrieval Augmented Generation (RAG) systems. Large Language Models (LLMs) can retrieve relevant factual information from vast knowledge bases (indexed as vectors) to ground their responses, mitigating hallucinations and improving accuracy. This hybrid approach combines the generative power of LLMs with the precision of semantic retrieval.
The market for vector databases and vector search capabilities is experiencing rapid growth. According to industry reports, the global vector database market is projected to reach billions of dollars in the coming years, driven by the proliferation of AI-powered applications. Leading AI researchers and data science practitioners consistently emphasize the importance of robust vector search infrastructure for scalable and intelligent systems.
This "from scratch" tutorial also signifies the democratization of complex AI concepts. By illustrating the core mechanics with basic Python, it empowers developers to understand, adapt, and build upon these technologies without requiring specialized, proprietary tools. This accessibility fosters innovation and broader adoption.
Looking ahead, the field of vector search is set for continued evolution. Advances in embedding models will yield even richer and more nuanced semantic representations. Research into more efficient ANN algorithms will further enhance scalability for truly massive datasets. Furthermore, hybrid search approaches, combining traditional keyword search with vector search, are gaining traction to leverage the strengths of both methodologies, offering comprehensive and highly relevant results. The future of information retrieval is undeniably semantic, and demonstrations like this NumPy implementation provide a crucial educational bridge for developers to participate in this exciting frontier.
Conclusion: Empowering Developers in the Age of AI
The construction of a vector search engine using minimal Python libraries is more than just a technical exercise; it’s a powerful statement about the accessibility and foundational nature of semantic search. By stripping away complexity and focusing on core mathematical principles, the demonstration illuminates how geometric relationships in high-dimensional space can unlock profound semantic understanding. This capability is indispensable for modern applications, from enhancing user experience in digital platforms to providing contextual grounding for cutting-edge generative AI. As AI continues to reshape industries, the ability to build and understand such fundamental components becomes increasingly vital, empowering developers to innovate and drive the next wave of intelligent systems.













Leave a Reply