
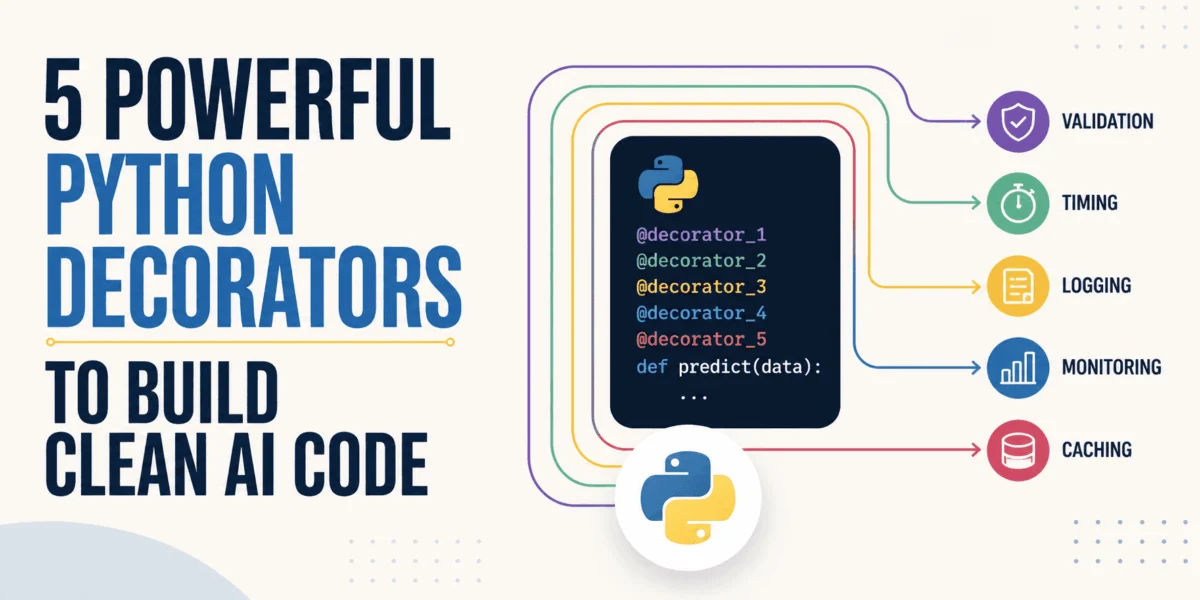
The burgeoning field of artificial intelligence and machine learning necessitates not only sophisticated algorithms but also robust, maintainable, and scalable software infrastructure. As AI systems integrate more deeply into production environments, the clarity and efficiency of the underlying codebase become paramount. Python decorators, a powerful linguistic feature, offer an elegant solution to manage the inherent complexity of AI and machine learning system development. They facilitate the crucial separation of core logic—such as model architectures and data pipelines—from peripheral, yet essential, boilerplate tasks like logging, timing, validation, and error handling. This strategic separation enhances code readability, reduces redundancy, and significantly improves overall project maintainability, a critical factor in the long-term success of any AI initiative.
Recent industry reports underscore the growing complexity of AI deployments. A 2023 survey by Gartner indicated that technical debt and integration challenges are among the top impediments to AI adoption. Python decorators directly address these issues by promoting modularity and adherence to the "Don’t Repeat Yourself" (DRY) principle, allowing developers to encapsulate cross-cutting concerns effectively. This article delves into five particularly impactful Python decorators, identified through extensive developer experience, that have consistently proven effective in refining AI codebases for improved clarity, performance, and resilience. The provided code examples, while concise, adhere to Python’s standard libraries and best practices, including the use of functools.wraps, ensuring that the illustrative logic is easily adaptable to diverse AI coding projects.
The Evolving Landscape of AI Development and the Role of Decorators
The journey of an AI model, from initial experimentation in a Jupyter notebook to full-scale deployment in a production environment, is fraught with challenges. Developers must contend with issues ranging from managing external API dependencies and ensuring data consistency to debugging performance anomalies and maintaining reproducibility across various development stages. In this context, Python decorators emerge as a versatile tool, enabling developers to inject functionality without altering the core logic of functions or methods. This aspect is particularly valuable in AI, where the rapid iteration of models and data pipelines often requires flexible and non-invasive modifications to code behavior. The following sections explore specific decorators that address common pain points throughout the AI/ML lifecycle.
1. Concurrency Limiter: Navigating External API Constraints
In modern AI applications, especially those leveraging large language models (LLMs) or other cloud-based AI services, interaction with third-party APIs is a common necessity. However, these external services frequently impose stringent rate limits, particularly on free or lower-tier usage plans. Exceeding these limits due to uncontrolled asynchronous requests can lead to service interruptions, error cascades, and degraded application performance. The Concurrency Limiter decorator provides a robust throttling mechanism, mitigating these risks by regulating the number of simultaneous asynchronous calls to external services.
- Background and Context: The proliferation of sophisticated pre-trained models accessible via APIs, such as OpenAI’s GPT series or Google’s PaLM, has democratized AI development. However, relying on these services introduces external dependencies and operational constraints. Developers often face
429 Too Many Requestserrors, leading to application instability. This problem is exacerbated in highly parallel processing scenarios common in AI, such as batch inference or embedding generation. - Mechanism and Implementation: The decorator utilizes
asyncio.Semaphore, a fundamental primitive for controlling access to a shared resource by multiple coroutines. A semaphore is initialized with alimitvalue, representing the maximum number of concurrent operations allowed. When anasyncfunction decorated with@limit_concurrencyis called, it attempts to acquire a permit from the semaphore. If the limit has been reached, the function pauses execution until a permit becomes available, ensuring that the number of concurrently executing functions never exceeds the predefined threshold. Once the function completes, the permit is released. This proactive approach prevents resource exhaustion and respects API usage policies. - Implications and Benefits:
- System Stability: Prevents cascading failures caused by external API rate limits, ensuring consistent application uptime.
- Cost Management: For usage-based APIs, controlled concurrency can help manage consumption and avoid unexpected overages.
- Improved User Experience: Reduces the likelihood of users encountering errors due to API unavailability, leading to a smoother application experience.
- Resource Optimization: Prevents local systems from being overwhelmed by an excessive number of pending network requests.
- Supporting Data/Industry Relevance: As of 2023, cloud service providers consistently report rate limiting as a common defensive measure against abuse and resource strain. Developers frequently report that managing API limits is a non-trivial challenge, often leading to custom, ad-hoc solutions if not handled systematically. Adopting a decorator-based approach standardizes this crucial aspect of system resilience.
import asyncio
from functools import wraps
def limit_concurrency(limit=5):
"""
Limits the number of concurrent executions of an asynchronous function.
Useful for managing API rate limits.
"""
sem = asyncio.Semaphore(limit)
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
async with sem:
return await func(*args, **kwargs)
return wrapper
return decorator
# Application Example: Managing LLM batch requests
# @limit_concurrency(5)
# async def fetch_llm_batch(prompt):
# # Simulate an async API call
# await asyncio.sleep(1)
# return f"Response for: prompt"
# # Example usage:
# async def main():
# prompts = [f"prompt_i" for i in range(20)]
# tasks = [fetch_llm_batch(p) for p in prompts]
# results = await asyncio.gather(*tasks)
# print(results)
# if __name__ == "__main__":
# asyncio.run(main())2. Structured Machine Learning Logger: Enhanced Observability for Complex Systems
In the intricate world of machine learning systems, where data flows through multiple transformations, models undergo iterative training, and predictions are generated in real-time, simple print() statements quickly become insufficient. Once deployed in production, particularly within microservices architectures or distributed computing environments, unstructured logs are easily lost in a sea of information, making debugging and performance monitoring a formidable task. The Structured Machine Learning Logger decorator addresses this by systematically capturing function executions and errors, formatting them into easily searchable JSON logs.
- Background and Context: The shift from monolithic applications to distributed microservices for AI deployment has amplified the need for centralized, structured logging. Traditional text-based logs, while readable, are difficult to parse, aggregate, and analyze programmatically. In a neural network training pipeline, for instance, a single epoch involves numerous sub-steps, each of which might generate critical information regarding data loading, model forward/backward passes, and metric updates. Losing track of these events can severely impede troubleshooting and performance optimization.
- Mechanism and Implementation: This decorator leverages Python’s built-in
loggingmodule and thejsonlibrary. Before and after the execution of the decorated function, it records metadata such as the function’s name (func.__name__), execution status (successorerror), and elapsed time. In the event of an exception, it captures the error message. All this information is then serialized into a JSON string, ensuring that each log entry is a self-contained, machine-readable record. This structure allows for seamless integration with log aggregation platforms like ELK Stack (Elasticsearch, Logstash, Kibana), Splunk, or cloud-native logging services (e.g., AWS CloudWatch, Google Cloud Logging). - Implications and Benefits:
- Rapid Debugging: Structured logs enable quick searching and filtering based on specific fields (e.g.,
step,status,error), drastically reducing the time spent identifying root causes of issues. - Proactive Monitoring: Integrates with monitoring tools to create dashboards and alerts, providing real-time insights into system health and performance.
- Performance Analysis: Time-stamped logs allow for precise measurement of function execution durations, aiding in bottleneck identification and optimization efforts.
- Auditability and Compliance: Provides a clear, immutable record of system operations, which can be crucial for regulatory compliance and auditing.
- Rapid Debugging: Structured logs enable quick searching and filtering based on specific fields (e.g.,
- Supporting Data/Industry Relevance: A report by Datadog in 2022 highlighted that 70% of organizations with complex cloud environments struggle with log management. The adoption of structured logging is a cornerstone of modern observability practices, with major cloud providers and MLOps platforms strongly advocating for it. The template provided is ideal for decorating critical steps within an ML pipeline, such as a
train_epochfunction, ensuring every training iteration’s outcome is meticulously recorded.
import logging, json, time
from functools import wraps
# Configure basic logging for demonstration. In a real application,
# this would be more sophisticated (e.g., to a file or external service).
logging.basicConfig(level=logging.INFO, format='%(message)s')
def json_log(func):
"""
Decorates a function to log its execution details (success/failure, time)
in a structured JSON format.
"""
@wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
try:
res = func(*args, **kwargs)
logging.info(json.dumps(
"step": func.__name__,
"status": "success",
"time_taken_seconds": round(time.time() - start, 4),
"args": [str(a) for a in args], # Example: log arguments
"kwargs": k: str(v) for k, v in kwargs.items() # Example: log keyword arguments
))
return res
except Exception as e:
logging.error(json.dumps(
"step": func.__name__,
"status": "error",
"time_taken_seconds": round(time.time() - start, 4),
"error_type": type(e).__name__,
"error_message": str(e)
))
raise # Re-raise the exception after logging
return wrapper
# Application Example: Training an epoch
# @json_log
# def train_epoch(model_name, training_data_size):
# # Simulate training
# if training_data_size < 100:
# raise ValueError("Training data too small for meaningful epoch.")
# time.sleep(0.5) # Simulate work
# return f"Model model_name trained on training_data_size samples."
# class MockModel:
# def fit(self, data):
# return "Model fitted successfully."
# # Example usage
# try:
# train_epoch("ResNet50", 1000)
# train_epoch("VGG16", 50) # This will raise an error
# except ValueError as e:
# print(f"Caught expected error: e")3. Feature Injector: Ensuring Data Consistency in Production
One of the most persistent challenges in deploying machine learning models is ensuring that the data presented to the model during inference is processed identically to the data used during training. This "training-serving skew" can severely degrade model performance in production, often manifesting as subtle, hard-to-debug issues. The Feature Injector decorator provides an elegant solution, automating the consistent generation of features from raw incoming data, particularly vital when transitioning models from exploratory environments (like Jupyter notebooks) to lightweight production settings, such as a FastAPI endpoint.
- Background and Context: In the iterative development cycle of an ML project, data scientists often perform various feature engineering steps within notebooks. These transformations—scaling, encoding, imputation, or creating new features from existing ones—are critical for model performance. However, when the model is deployed, raw user input must undergo the exact same sequence of transformations. Manually replicating and maintaining these preprocessing steps across different codebases (training script vs. serving API) is a common source of errors and operational overhead. MLOps principles strongly advocate for versioning and reusability of data pipelines to prevent such inconsistencies.
- Mechanism and Implementation: The
add_weekend_featuredecorator illustrates this by taking a Pandas DataFrame as input. It first creates a copy of the DataFrame (df.copy()) to preventSettingWithCopyWarningand ensure immutability of the original input. It then adds a newis_weekendcolumn based on thedatecolumn, applying the same logic that would have been used during training. The decorated function then receives this augmented DataFrame, guaranteeing that the required feature is present and correctly calculated before any subsequent processing or model inference. This approach centralizes feature generation logic, making it easier to update and maintain. - Implications and Benefits:
- Eliminates Training-Serving Skew: Guarantees that the data presented to the model in production has the same features and format as the data it was trained on, leading to more reliable predictions.
- Simplified Deployment: Streamlines the deployment process by encapsulating complex feature engineering logic within reusable decorators, reducing the burden on API developers.
- Improved Maintainability: Centralizes feature creation, making it easier to update or modify features across the entire ML pipeline without scattering logic.
- Enhanced Reliability: Reduces the risk of subtle bugs arising from inconsistent data transformations, which are notoriously difficult to diagnose in production.
- Supporting Data/Industry Relevance: According to Google’s "Rules of Machine Learning," "Don’t fight the data" and "The best way to make sure that a feature is used in a consistent way is to apply the same code to generate it in all places." This decorator directly implements this best practice. The problem of inconsistent feature generation is a well-documented cause of model degradation in real-world applications, often leading to significant performance drops and requiring costly debugging efforts.
from functools import wraps
import pandas as pd
import datetime
def add_weekend_feature(func):
"""
Decorates a function that processes a DataFrame to add an 'is_weekend' feature
based on a 'date' column.
"""
@wraps(func)
def wrapper(df, *args, **kwargs):
if not isinstance(df, pd.DataFrame):
raise TypeError("Input must be a Pandas DataFrame.")
if 'date' not in df.columns:
raise ValueError("DataFrame must contain a 'date' column.")
df_copy = df.copy() # Prevents Pandas mutation warnings
# Ensure 'date' column is datetime type
df_copy['date'] = pd.to_datetime(df_copy['date'])
df_copy['is_weekend'] = df_copy['date'].dt.dayofweek.isin([5, 6]).astype(int)
return func(df_copy, *args, **kwargs)
return wrapper
# Application Example: Processing data for a model
# @add_weekend_feature
# def process_data(df):
# # 'is_weekend' is guaranteed to exist here
# print(f"DataFrame columns after feature injection: df.columns.tolist()")
# print(df[['date', 'is_weekend']].head())
# return df.dropna()
# # Example usage
# data = 'date': [datetime.date(2023, 1, 1), datetime.date(2023, 1, 2),
# datetime.date(2023, 1, 7), datetime.date(2023, 1, 8)],
# 'value': [10, 20, None, 40]
# df_input = pd.DataFrame(data)
# processed_df = process_data(df_input)
# print("nProcessed DataFrame:")
# print(processed_df)4. Deterministic Seed Setter: Ensuring Reproducibility in Experimentation
Reproducibility is a cornerstone of scientific research and a critical requirement in machine learning development. When experimenting with models, adjusting hyperparameters, or conducting A/B tests, uncontrolled randomness can obscure the true impact of changes, leading to misleading conclusions. The Deterministic Seed Setter decorator addresses this by locking the random seed for key libraries, thereby ensuring that any operations relying on pseudo-random number generation produce identical results across different runs. This is particularly vital during experimentation and hyperparameter tuning phases of the AI/ML lifecycle.
- Background and Context: Machine learning models inherently rely on randomness for various operations: initializing model weights, shuffling data for training batches, generating random subsets for sampling or cross-validation, and implementing techniques like dropout. If these random processes are not controlled, a change in model performance could be attributed to a new hyperparameter setting when, in reality, it’s merely a consequence of a different random initialization. This makes comparing model versions, debugging performance regressions, and collaborating on research incredibly difficult.
- Mechanism and Implementation: The
lock_seeddecorator takes an integerseedas an argument. Inside thewrapperfunction, it sets the seed for Python’s built-inrandommodule andnumpy‘s random number generator (np.random.seed). For deep learning frameworks like TensorFlow or PyTorch, additional calls to their respective seeding functions (e.g.,tf.random.set_seed,torch.manual_seed) would be included within the decorator. By wrapping functions that involve random operations, this decorator ensures that every time the decorated function is called, the random number generators are reset to a known state, guaranteeing reproducible outcomes for the operations within that function. - Implications and Benefits:
- Reliable Experimentation: Isolates the effect of specific changes (e.g., new model architecture, different learning rate) by eliminating variability due to random initialization, making A/B tests and hyperparameter tuning results truly comparable.
- Efficient Debugging: When a model’s performance drops, a locked seed helps determine if the issue is a code change, a data problem, or simply a "bad" random initialization.
- Scientific Rigor: Ensures that research findings and model performance metrics are reproducible, building trust and facilitating peer review in academic and industrial settings.
- Collaborative Development: Allows multiple developers to work on the same codebase and reproduce each other’s results, streamlining teamwork.
- Supporting Data/Industry Relevance: The importance of reproducibility is a recurring theme in ML conferences and research papers. Major ML frameworks provide explicit functions for setting seeds, underscoring this need. A study published in Nature in 2016 estimated that over half of scientific research findings are not reproducible, highlighting a critical challenge that tools like this decorator help address in the computational sciences.
import random, numpy as np
from functools import wraps
def lock_seed(seed=42):
"""
Decorates a function to set deterministic seeds for random and numpy
within its scope, ensuring reproducibility.
"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
# Store current states to restore later if needed,
# though for simple reproducibility within the function,
# just setting is often enough.
current_random_state = random.getstate()
current_np_state = np.random.get_state()
random.seed(seed)
np.random.seed(seed)
# Add other framework seeds here if applicable (e.g., torch.manual_seed, tf.random.set_seed)
try:
return func(*args, **kwargs)
finally:
# Optionally restore original states if the decorator's impact
# should be strictly confined to the decorated function.
random.setstate(current_random_state)
np.random.set_state(current_np_state)
return wrapper
return decorator
# Application Example: Initializing weights for a neural network layer
# @lock_seed(42)
# def initialize_weights():
# print(f"Random float from 'random': random.random()")
# print(f"Numpy random array: np.random.randn(2, 2)")
# return np.random.randn(10, 10)
# # Example usage:
# print("First call:")
# _ = initialize_weights()
# print("nSecond call (should be identical random output within function):")
# _ = initialize_weights()5. Dev-Mode Fallback: Enhancing Resilience and Developer Productivity
Modern AI applications, especially those built on top of external services like LLMs (e.g., Retrieval-Augmented Generation systems), are inherently dependent on the availability and responsiveness of these external components. During local development, continuous integration/continuous deployment (CI/CD) testing, or even in production, external factors such as connection timeouts, API rate limits, or service outages can cause decorated functions to fail. The Dev-Mode Fallback decorator provides a crucial safety net: instead of allowing an exception to halt execution, it intercepts the error and returns a predefined set of "mock test data."
- Background and Context: Developing and testing applications that rely heavily on external APIs can be slow, costly, and unreliable. API calls introduce network latency, consume usage credits, and are susceptible to external service downtime. In a development environment, waiting for real API responses or dealing with intermittent failures can significantly impede developer productivity. Similarly, in CI/CD pipelines, flaky tests due to external dependencies can lead to false negatives and wasted compute resources. The need for a graceful degradation mechanism is paramount.
- Mechanism and Implementation: The
fallback_mockdecorator is a higher-order function that takesmock_dataas an argument. The innerwrapperfunction attempts to execute the decorated function within atry-exceptblock. If anyExceptionoccurs during the execution (e.g., aTimeoutErrorfrom a network call, anHTTPErrorindicating a rate limit), the decorator catches it and, instead of re-raising, returns themock_data. This allows the rest of the application to continue functioning with simulated data, providing a predictable and stable environment for development and testing. The specificmock_datashould be carefully chosen to mimic the expected output of the function, ensuring downstream components can still operate. - Implications and Benefits:
- Enhanced Developer Productivity: Developers can work offline or without incurring API costs, rapidly iterating on application logic without waiting for or being blocked by external services.
- Robust CI/CD Pipelines: Eliminates flaky tests caused by transient external API failures, leading to faster and more reliable automated testing.
- System Resilience: Ensures graceful degradation in production. If an external service temporarily fails, the application can continue to function, albeit with mock data, preventing a complete outage.
- Cost Savings: Reduces reliance on expensive API calls during development and testing phases.
- Supporting Data/Industry Relevance: According to a 2022 survey by SlashData, 45% of developers report that managing third-party APIs is a significant challenge. The concept of "circuit breakers" and "fallback mechanisms" is a standard pattern in resilient software architecture, particularly in microservices. This decorator provides a simple yet effective implementation of this principle, saving countless hours in debugging and ensuring application continuity.
from functools import wraps
def fallback_mock(mock_data):
"""
Decorates a function to return predefined mock_data if an exception occurs
during its execution. Useful for development and testing with external APIs.
"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as e: # Catches timeouts, rate limits, connection errors, etc.
print(f"Warning: Function 'func.__name__' failed with exception: e. Returning mock data.")
return mock_data
return wrapper
return decorator
# Application Example: Getting text embeddings from an external API
# class ExternalAPIClient:
# def embed(self, text):
# # Simulate an API call that might fail
# if "error" in text:
# raise ConnectionError("Simulated API connection timeout or rate limit.")
# return [len(text) * 0.01, -0.05, 0.02] # Simple mock embedding logic
# external_api = ExternalAPIClient()
# @fallback_mock(mock_data=[0.0, 0.0, 0.0]) # Default fallback embedding
# def get_text_embeddings(text):
# return external_api.embed(text)
# # Example usage:
# print(f"Embeddings for 'hello world': get_text_embeddings('hello world')")
# print(f"Embeddings for 'this text will cause an error': get_text_embeddings('this text will cause an error')")Wrapping Up: Decorators as Pillars of Robust AI Engineering
The journey through these five Python decorators reveals their profound utility in constructing cleaner, more resilient, and more maintainable AI and machine learning systems. From precisely controlling concurrency to external APIs and ensuring structured, searchable logging for complex pipelines, to guaranteeing data consistency during model inference, locking random seeds for rigorous experimentation, and providing robust fallbacks for external service dependencies, decorators empower developers to tackle critical engineering challenges with elegance and efficiency.
These patterns are not merely syntactic sugar; they represent fundamental principles of good software engineering—separation of concerns, reusability, and defensive programming—applied effectively to the unique demands of AI development. By encapsulating cross-cutting concerns, Python decorators enable AI practitioners to focus on the core innovation of their models and algorithms, while offloading boilerplate and operational complexities to well-tested, reusable components. As AI systems continue to grow in scale and intricacy, the strategic adoption of such Pythonic tools will become increasingly indispensable for fostering robust, scalable, and production-ready machine learning solutions, thereby contributing significantly to the broader success and impact of artificial intelligence in the real world. The insights shared by AI leaders like Iván Palomares Carrascosa, who advocates for these practices, underscore the growing recognition of engineering excellence as a cornerstone of advanced AI development.











Leave a Reply