
For years, the pathway to a data job appeared straightforward: master SQL and Python, and opportunities would follow. This formula proved particularly effective as mid-sized companies began their journey to becoming "data-driven." Hiring managers were content with candidates who could execute a functional GROUP BY query and manipulate a pandas DataFrame without significant errors. A basic understanding of PostgreSQL was often enough to secure a position. This approach served the industry well for a period, but that era has definitively concluded.
The data professional’s job market has undergone a profound structural transformation, driven by rapid technological advancements and evolving business needs. While SQL and Python remain undeniably important—appearing on virtually every job description—their status has shifted dramatically. They are no longer the primary differentiators that set candidates apart; instead, they have been demoted to fundamental prerequisites. This shift signifies a growing chasm between the skills many candidates diligently prepare for, often based on outdated market demands, and the sophisticated capabilities companies actively seek today. This article delves into this critical skill gap, outlining the new competencies required to thrive in the contemporary data landscape.

The Evolving Landscape of Data Professional Demands
The early 2010s saw the nascent stages of the "data scientist" role, often described as a "unicorn" position requiring expertise across statistics, computer science, and domain knowledge. Python and R emerged as dominant tools for statistical modeling and early machine learning. As the decade progressed, the sheer volume of data necessitated robust data management, elevating SQL to an indispensable skill for accessing and manipulating relational databases. Python continued its ascent, becoming the lingua franca for data scripting, analysis, and foundational machine learning tasks. This period fostered an environment where a strong grasp of these two languages, coupled with statistical acumen, was indeed a powerful differentiator. Companies focused on initial data extraction, basic analytics, and building foundational dashboards.
However, the rapid acceleration of artificial intelligence, machine learning operations (MLOps), and advanced data engineering practices has reshaped expectations. Businesses are no longer merely "data-driven"; they aspire to be "AI-first," integrating predictive and generative capabilities into core operations. This ambition demands a more comprehensive skill set from data professionals, moving beyond mere analysis to encompass system design, deployment, and maintenance.
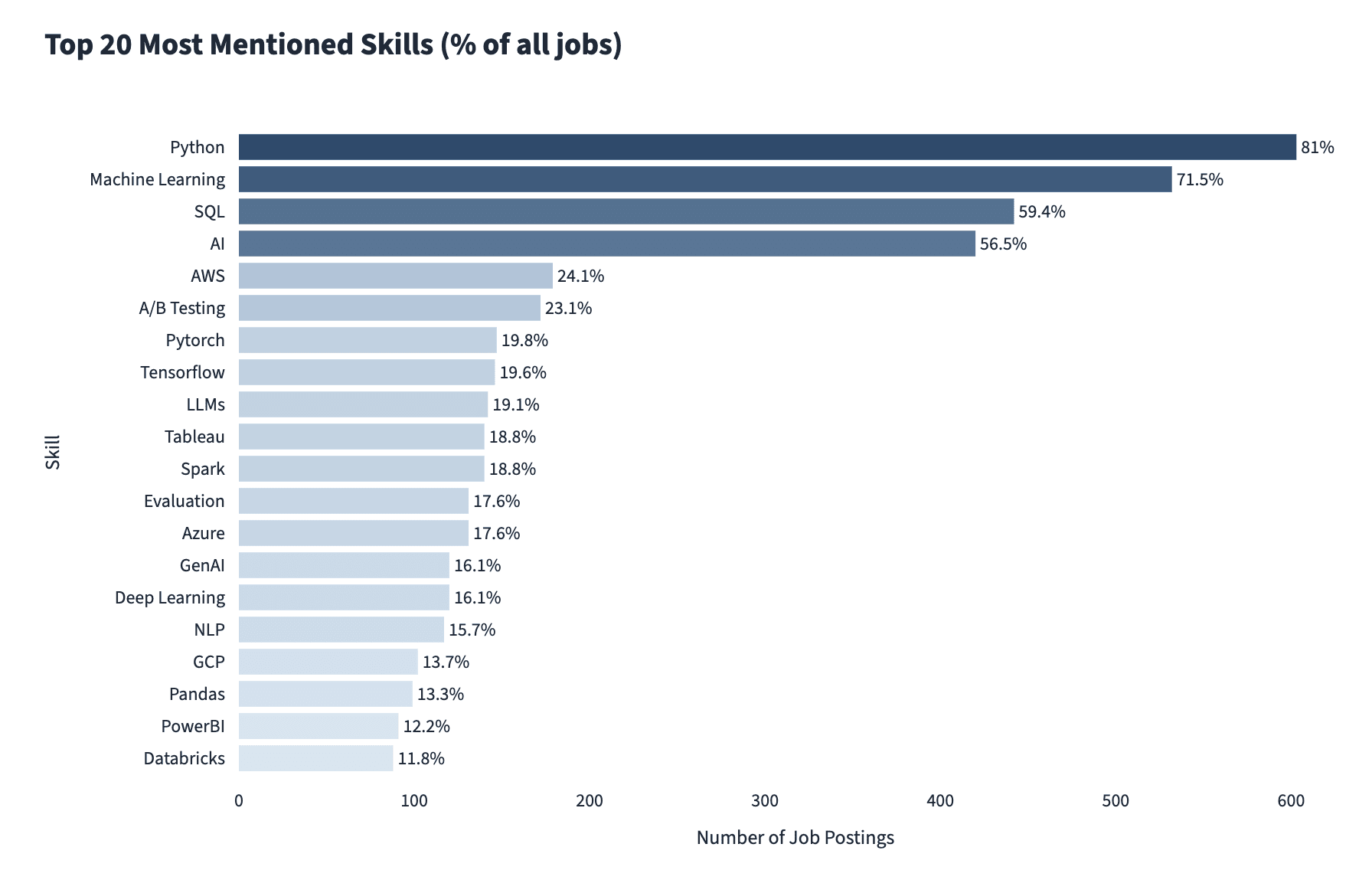
A comprehensive analysis conducted in January 2026 by Future Proof Data Science, examining over 700 data scientist job postings, starkly illustrates this shift. The report confirmed that Python and SQL continue to rank among the top three most requested skills. However, machine learning and AI competencies have surged, securing the second and fourth positions, respectively. Critically, the study revealed that approximately one in three AI-related postings now mandates hands-on AI expertise, a significant increase from previous years. Specific AI skills frequently cited include proficiency in deep learning frameworks like TensorFlow and PyTorch, natural language processing (NLP), computer vision, reinforcement learning, and, increasingly, generative AI and large language models (LLMs) alongside vector databases and prompt engineering. This trend underscores an escalating demand for data professionals capable of not just understanding AI models, but actively building, deploying, and managing complex AI systems.

Beyond the visible rise of AI, a less apparent but equally critical shift has occurred: the foundational engineering bar for data professionals has risen sharply. Skills traditionally associated with data engineering—such as designing and managing data pipelines, orchestrating complex workflows, leveraging cloud platforms, and implementing robust data quality checks—are now core expectations for many data science roles. Similarly, expertise in machine learning in production, encompassing model monitoring, drift detection, and the design of rigorous evaluation frameworks, is no longer a bonus but a standard requirement. A quick survey of major job boards corroborates this, with "Data Scientist" roles routinely listing proficiency in platforms like Snowflake, dbt (data build tool), and Apache Airflow, along with ownership of ETL (Extract, Transform, Load) pipelines, as mandatory skills rather than desirable additions. This convergence of analytical, machine learning, and engineering responsibilities creates a new imperative for data professionals to acquire a broader and deeper technical foundation.
The New Differentiators: Four Essential Skills for Today’s Data Professionals
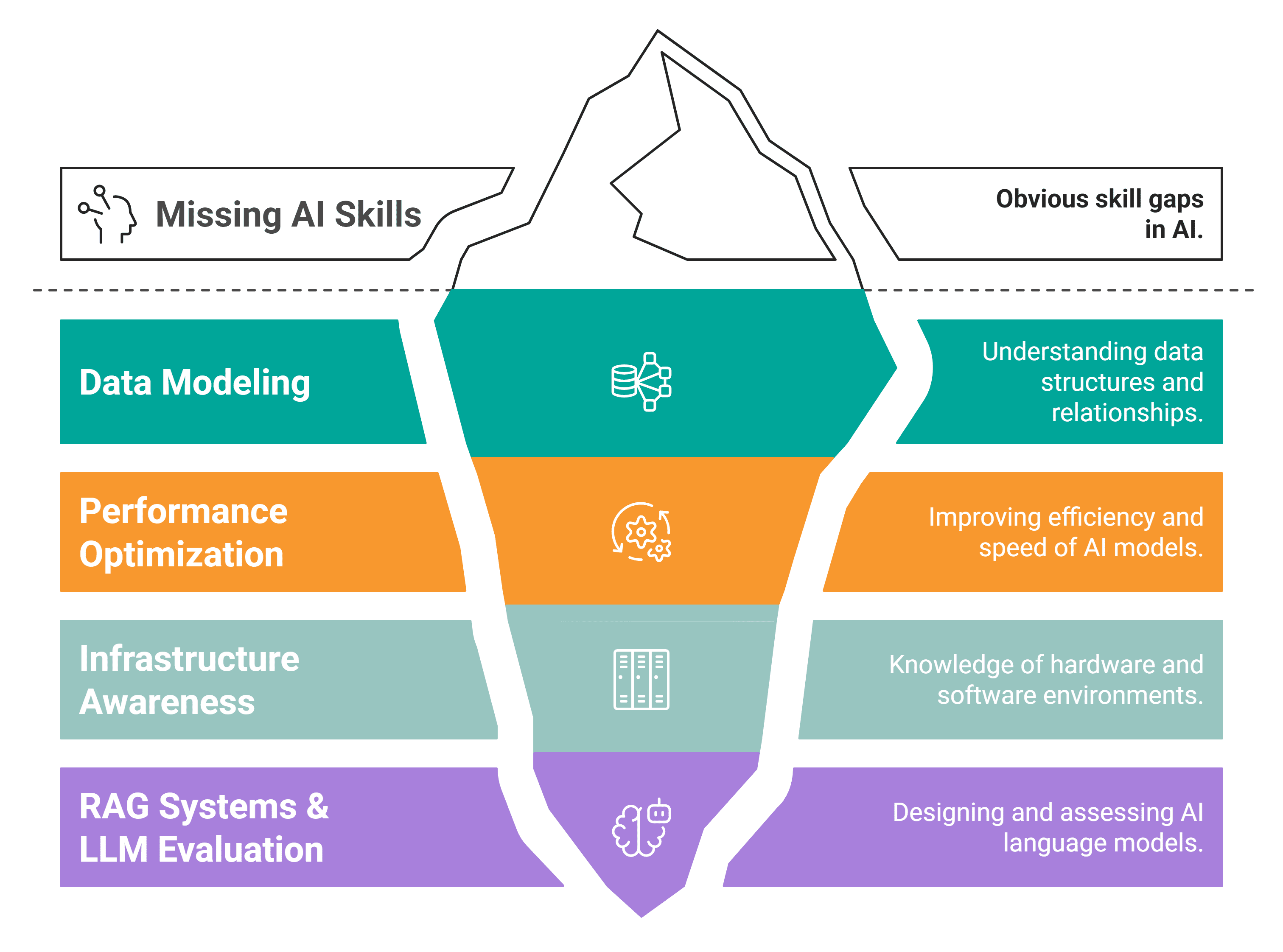
The modern data professional must cultivate a new suite of skills to remain competitive and effective. These four areas represent the new differentiators in the current job market, bridging the gap between traditional data science and the demands of an AI-first enterprise.
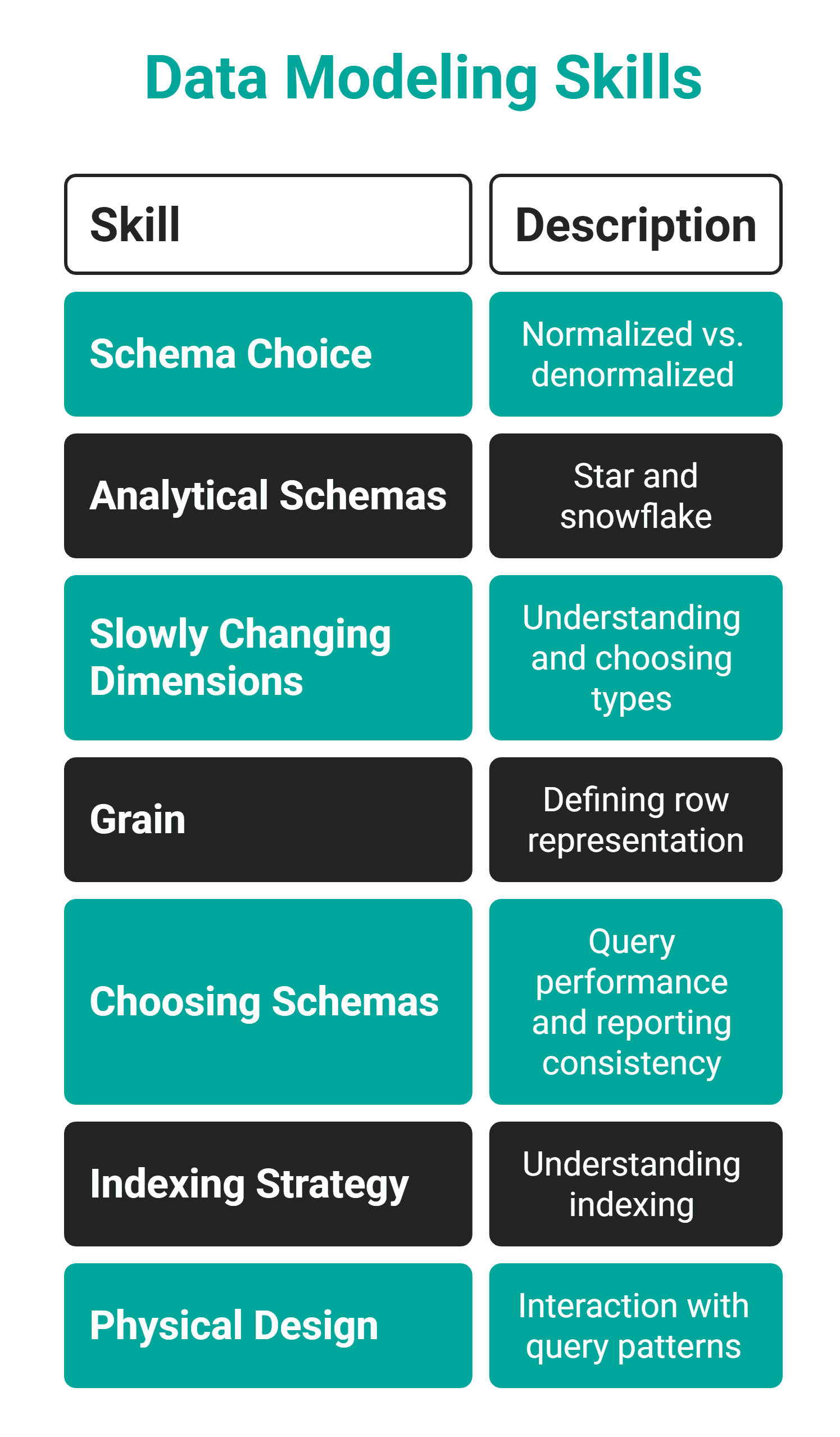
Skill #1: Data Modeling
What It Is: Data modeling is the critical ability to design how data should be structured, related, and ultimately stored within an organization’s data ecosystem. This involves making fundamental decisions about the creation of tables, defining their purpose and content, and establishing the relationships between them to ensure data integrity, accessibility, and utility. It’s the architectural blueprint for an organization’s data assets.
Why It Became a Differentiator: The proliferation of advanced data warehousing and transformation tools has fundamentally altered the landscape of data ownership. Platforms like Snowflake, dbt, and Google BigQuery have democratized access to the data transformation layer, making it significantly easier for data scientists to directly own and manage these processes. Consequently, data modeling decisions, which historically fell within the purview of data engineers, are increasingly being delegated to data scientists. The implications of flawed data modeling are profound and often insidious. Errors in data schema design may not manifest immediately but can lead to significant downstream problems. For instance, machine learning models built on feature engineering derived from data with incorrect granularity—a direct consequence of a poorly modeled foundation—can yield inaccurate predictions, erode trust, and result in costly business decisions. This shift necessitates that data scientists possess a deep understanding of how data is organized and transformed, enabling them to build robust and reliable data foundations for their analytical and machine learning endeavors.
How to Acquire It: To develop this skill, begin with a practical exercise: select a real dataset you frequently work with and undertake the task of redesigning its schema from the ground up. During this process, ask probing questions such as: "What are the core entities in this dataset?" "How do these entities relate to each other?" "What is the most granular level at which we need to analyze this data?" and "How can we structure this data to optimize for both analytical queries and machine learning feature generation?" Following this hands-on experience, delve into the principles of dimensional modeling. Ralph Kimball’s approach, meticulously detailed in his seminal work, The Data Warehouse Toolkit, remains an invaluable reference point for understanding how to design data warehouses for optimal business intelligence and reporting. Studying Kimball’s star schema and snowflake schema concepts will provide a robust theoretical framework to complement practical application.
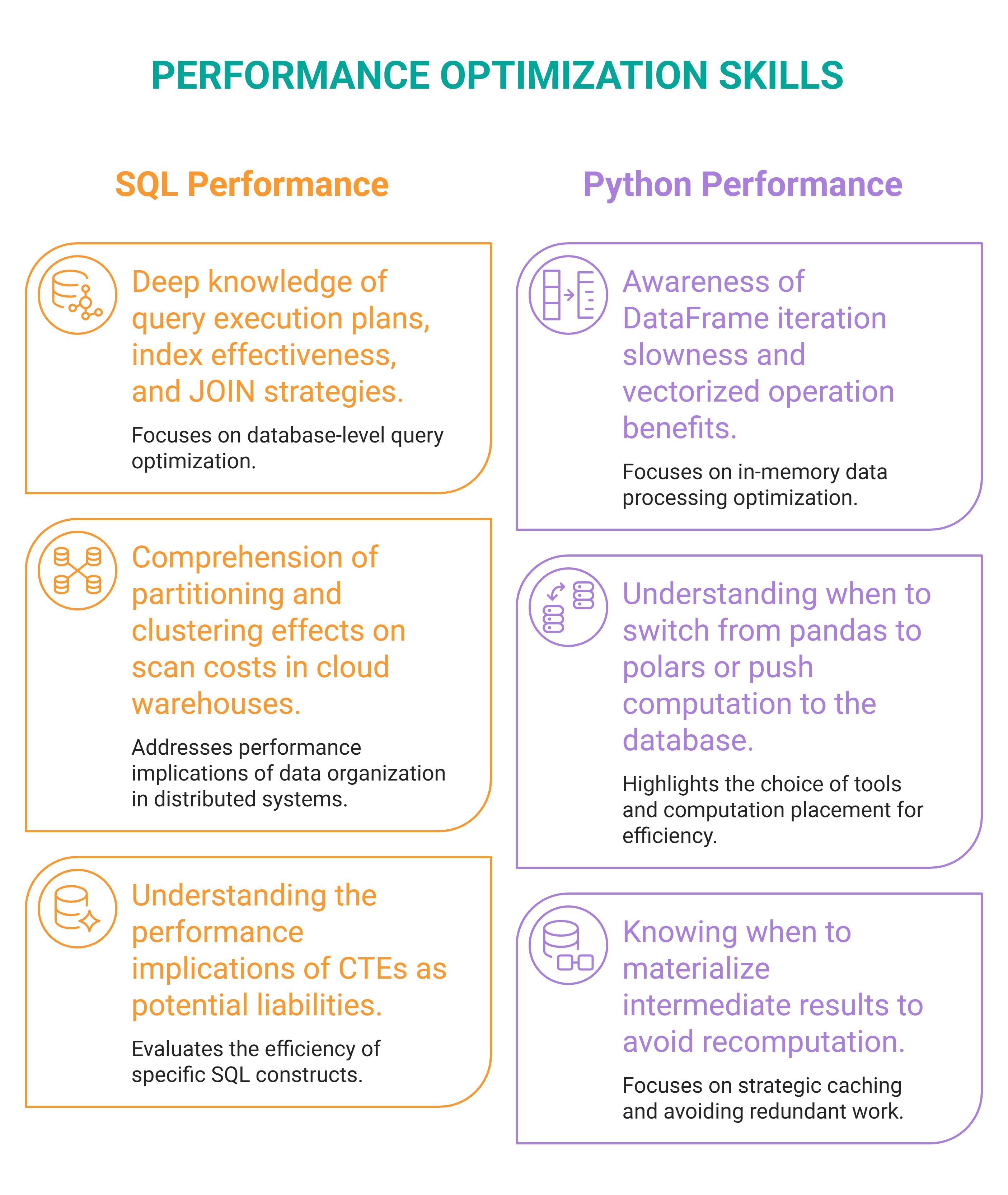
Skill #2: Performance Optimization
What It Is: Performance optimization encompasses the ability to understand the underlying mechanisms governing query execution and data pipeline operations, and subsequently to refine them for enhanced speed, reduced cost, and greater scalability. This applies not only to SQL queries but also to Python pipelines and broader data workflows, which data scientists are increasingly expected to manage end-to-end in production environments.
Why It Became a Differentiator: The exponential growth in data volumes has rendered inefficient code and queries untenable. A seemingly minor inefficiency can translate into hundreds or even thousands of dollars in cloud computing costs, alongside significant delays or timeouts in production systems. Industry reports frequently highlight that inefficient data processing is a major contributor to escalating cloud expenditure, with some estimates suggesting that companies waste upwards of 30% of their cloud budget due to suboptimal resource utilization. Moreover, as data scientists assume greater ownership of the entire data pipeline lifecycle, their code must transition from being merely functional in a Jupyter notebook to being production-ready, robust, and performant. This requires a deep understanding of how data systems operate under load and how to identify and eliminate bottlenecks. The ability to write and optimize high-performing code directly impacts an organization’s operational efficiency, cost-effectiveness, and the speed at which it can deliver insights and deploy AI models.
How to Acquire It: For SQL query optimization, select several complex queries you’ve authored and execute them with EXPLAIN ANALYZE (or its equivalent in your database system). Carefully interpret the output from the query planner to understand the actual execution path, identifying areas where indexes could be leveraged, table joins could be reordered, or subqueries could be rewritten for efficiency. This iterative process will reveal opportunities for substantial performance gains. For slow Python pipelines, profiling is indispensable. Tools like cProfile and line_profiler can pinpoint CPU-bound bottlenecks, while memory_profiler helps identify memory-intensive operations. The goal is to isolate the slowest or most resource-intensive parts of the code—for example, an unvectorized Python loop that should be replaced with NumPy operations, or data being loaded entirely into memory instead of processed in chunks—and implement targeted optimizations. Measuring the before-and-after performance will solidify your understanding and demonstrate the impact of your improvements.
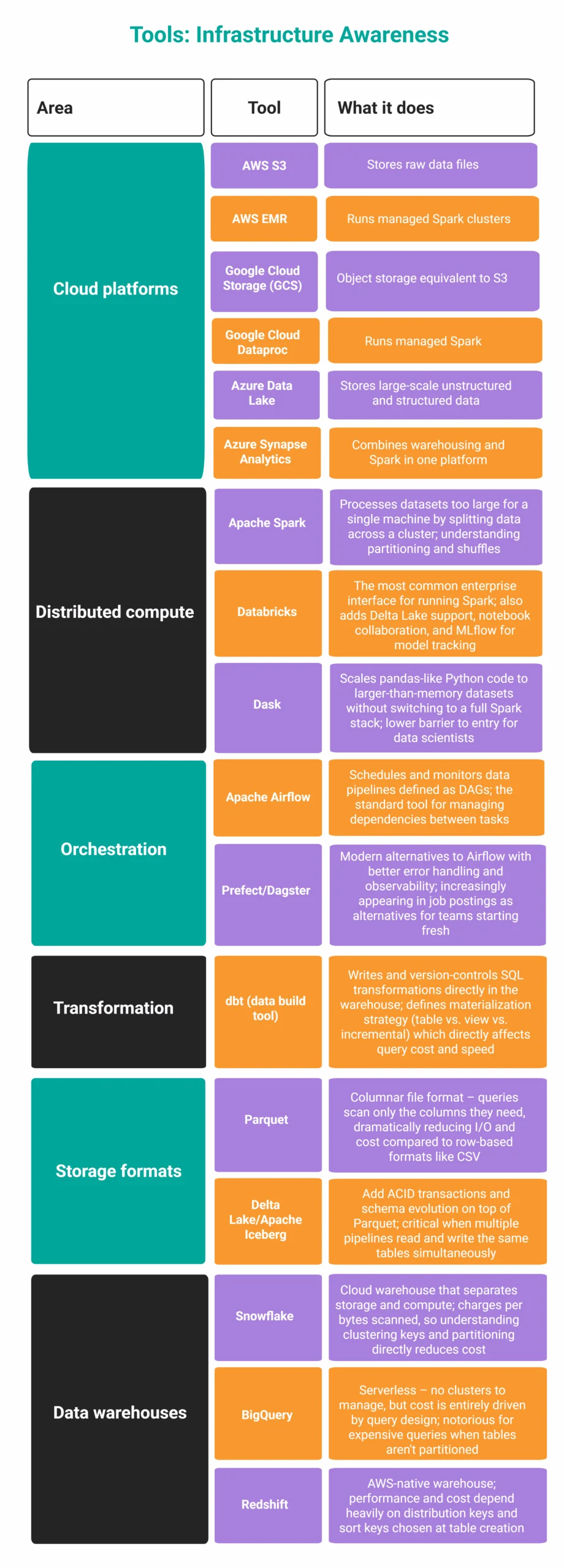
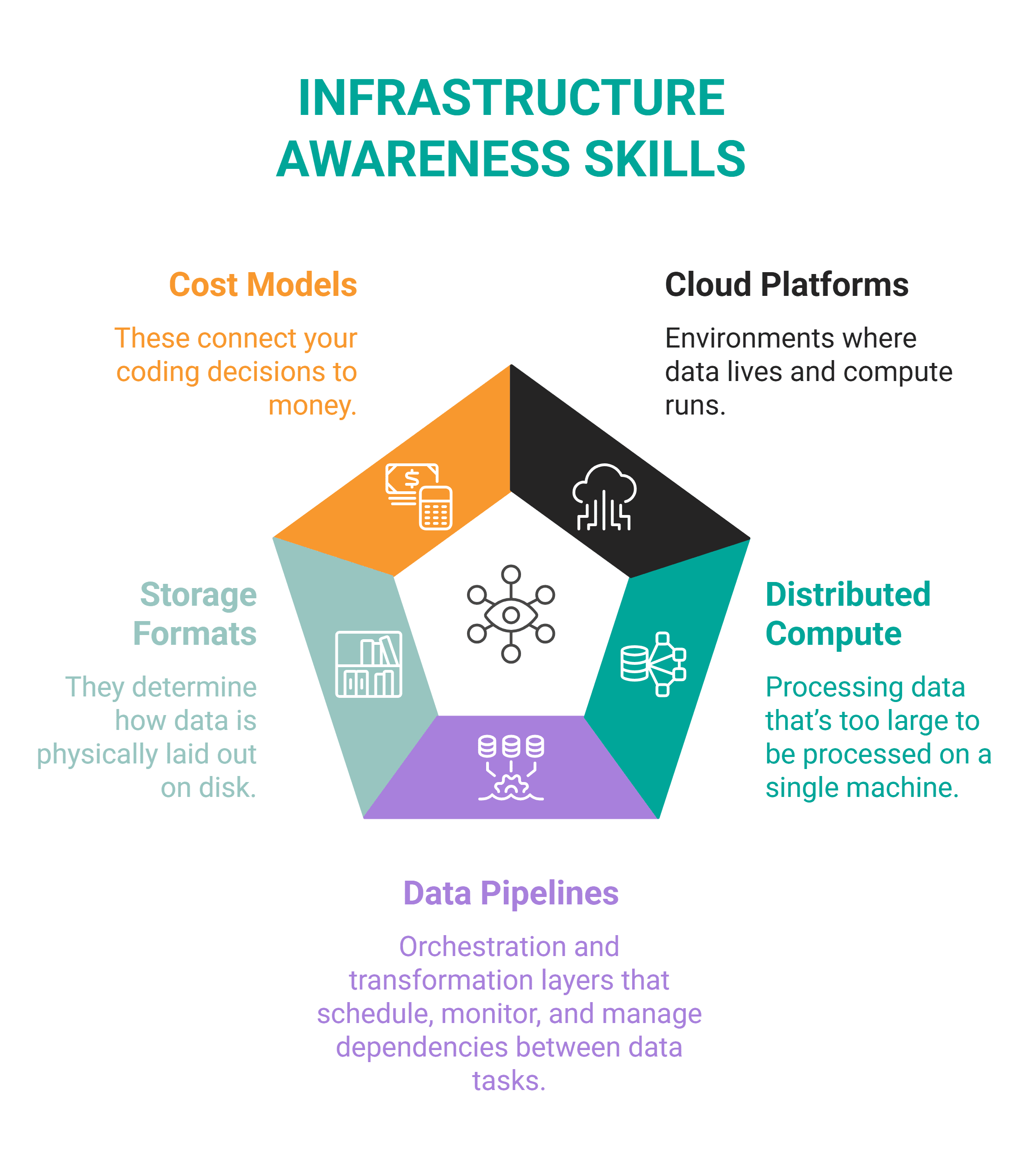
Skill #3: Infrastructure Awareness
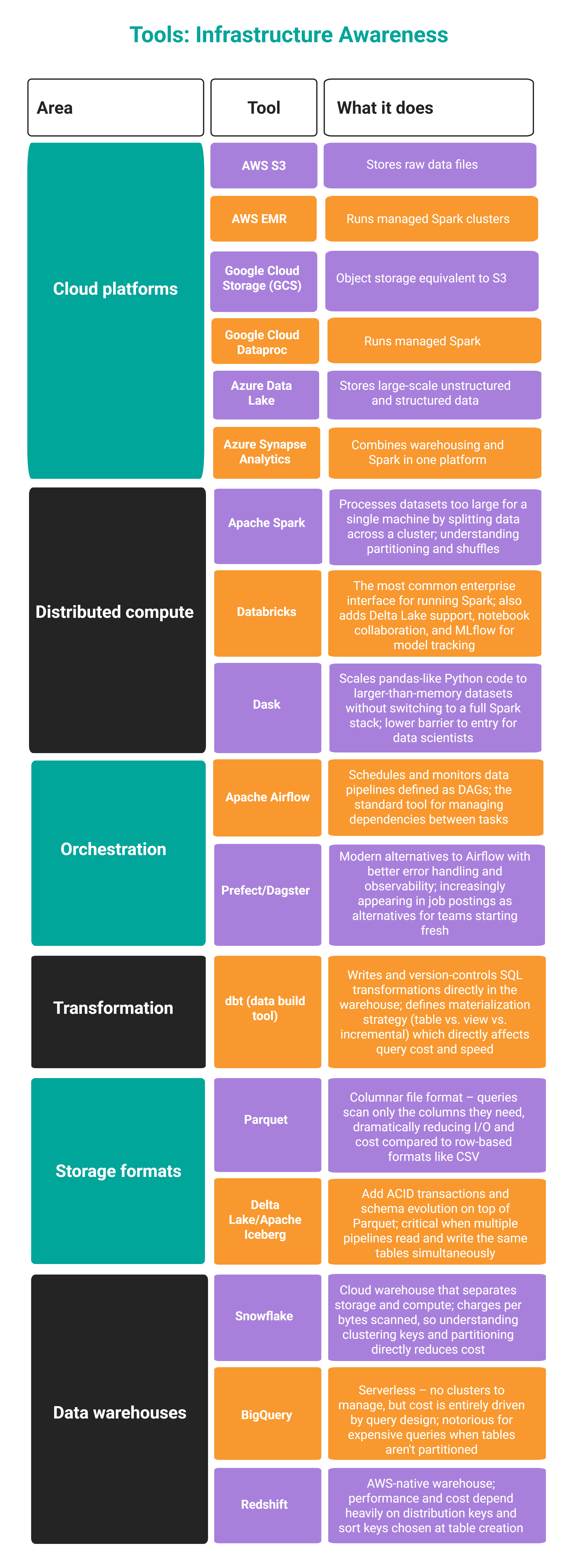
What It Is: Infrastructure awareness is the foundational understanding of the various systems through which data lives, moves, and is processed. This encompasses knowledge of cloud platforms (AWS, Azure, GCP), distributed compute paradigms (Spark, Dask), data pipelines, storage formats (Parquet, ORC), and the associated cost models. It means possessing sufficient insight into the underlying infrastructure to design data systems that are not only functional but also deployable, scalable, and cost-efficient within that environment.
Why It Became a Differentiator: The increasing confluence of data science and data engineering responsibilities means that data scientists can no longer operate in a vacuum, detached from the operational realities of data infrastructure. Relying solely on data engineers for every infrastructure-related decision creates an immediate bottleneck, hindering agility and delaying project deployment. Modern data organizations seek professionals who can independently navigate and contribute to infrastructure design and troubleshooting. This includes understanding core components like data ingestion mechanisms (e.g., Kafka, Kinesis), data warehousing solutions (e.g., Snowflake, Databricks), orchestration tools (e.g., Airflow, Prefect), and monitoring systems (e.g., Prometheus, Grafana). A data scientist with infrastructure awareness can design more robust solutions, communicate effectively with engineering teams, and even contribute to the maintenance and scaling of production systems, thereby accelerating the delivery of valuable data products and AI capabilities. This awareness is particularly crucial as organizations increasingly adopt DataOps and MLOps principles, which emphasize collaboration, automation, and continuous delivery across the data lifecycle.
How to Acquire It: A proactive approach involves arranging dedicated sessions with your data engineering team. Request a detailed walkthrough of a typical data pipeline, from source to consumption. Focus on understanding where data originates, how it is partitioned and stored, the transformation steps involved, and the procedures for handling failures or data quality issues. To gain hands-on experience, embark on building a small, end-to-end data pipeline yourself, utilizing free tiers offered by major cloud providers. This exercise should involve setting up data ingestion, basic transformations, and storage. Crucially, pay close attention to the cost and execution metrics associated with your pipeline. Furthermore, deliberately introduce errors or breakages into your pipeline to observe its failure modes and understand the recovery mechanisms, if any. This practical exposure will demystify complex infrastructure concepts and build confidence in designing deployable systems.
Skill #4: Designing RAG Systems, Evaluating LLM Outputs, and Running AI Experiments
What It Is: This cluster of skills pertains directly to practical applications of artificial intelligence, particularly in the realm of large language models (LLMs). It involves the ability to design Retrieval-Augmented Generation (RAG) systems—architectures that connect LLMs to proprietary or external data sources to enhance their factual accuracy and relevance. It also encompasses the crucial skill of building robust evaluation frameworks to objectively measure the performance and efficacy of LLM-powered features. Finally, it includes the capacity to design and execute rigorous experiments to test hypotheses about AI feature performance and impact.
Why It Became a Differentiator: The advent of powerful, accessible AI tools and frameworks has dramatically lowered the barrier to entry for developing sophisticated AI applications. Frameworks like LangChain and LlamaIndex, coupled with the rise of cloud-native vector databases, enable data professionals to construct RAG pipelines without requiring extensive deep learning research expertise. Consequently, the core challenge has shifted from "can it be built?" to "can it be built well, reliably evaluated, and trusted in a production environment?" Organizations now demand data scientists who can not only prototype AI features but also define clear metrics, design valid experiments, and accurately measure the outcomes of these features. This includes understanding bias, fairness, and explainability in AI, alongside practical deployment considerations. As AI becomes embedded in more products and services, the ability to ensure its quality, safety, and business impact through systematic evaluation and experimentation is paramount.
How to Acquire It: To cultivate these skills, begin by engaging with real-world AI product and Generative AI interview questions. Platforms like StrataScratch offer excellent resources for refining your thinking. Consider questions such as: "How would you measure the impact of an AI-powered inventory recommendation system being rolled out to a sample of retail stores? How would you design the experiment and account for store-level variation?" or "Describe how you would architect a RAG system from scratch. What components are needed, and how would you optimize retrieval quality?" After articulating your theoretical understanding, move to practical application: build a small RAG application. Choose a specific domain, embed a relevant document corpus into a vector database, wire up the retrieval mechanism, and then evaluate the LLM’s outputs using structured metrics (e.g., ROUGE scores, semantic similarity, or human evaluation). Concurrently, design a hypothetical experiment for an AI feature. Clearly state a hypothesis, define the key performance indicators (KPIs) or metrics for evaluation, and outline a valid experimental design (e.g., A/B test, quasi-experiment) to measure its impact. This blend of theoretical problem-solving and hands-on implementation will solidify your expertise in practical AI.
Industry Reactions and Broader Implications
The structural shift in the data professional job market has elicited varied reactions across the industry. Hiring managers are increasingly vocal about the struggle to find candidates who possess both strong analytical foundations and the necessary engineering and AI deployment skills. "We see a lot of candidates with strong academic backgrounds in statistics and machine learning, but they often lack the practical understanding of how to put models into production or design scalable data architectures," noted a Lead Data Scientist at a major tech firm, echoing a common sentiment. This often leads to longer hiring cycles and a greater emphasis on hands-on, project-based assessments during interviews.
Educational institutions and online learning platforms are also feeling the pressure to adapt. Many bootcamps and university programs are rapidly updating their curricula to incorporate MLOps principles, cloud infrastructure, and practical generative AI applications. However, the pace of technological change often outstrips the speed of curriculum development, creating a continuous challenge for educators to keep their offerings relevant.
For existing data professionals, this evolution underscores the imperative for continuous learning and upskilling. The lines between traditional data scientist, data engineer, and machine learning engineer are blurring, giving rise to "full-stack" data roles that demand a hybrid skill set. Professionals who embrace this multidisciplinary approach are better positioned for career advancement and resilience in a dynamic market. This trend is not merely about adding new tools to a resume; it’s about adopting a more holistic, product-oriented mindset that considers the entire lifecycle of data and AI solutions, from raw data to deployed, monitored, and optimized systems.
Conclusion
The data professional landscape has moved beyond the simple equation of SQL plus Python. While these foundational languages remain indispensable, they are now merely the entry points to a much more complex and demanding field. The emergence of new technologies, particularly in artificial intelligence, and the growing maturity of data engineering practices have created a distinct skill gap. The four critical competencies—data modeling, performance optimization, infrastructure awareness, and practical AI skills encompassing RAG design, LLM evaluation, and AI experimentation—represent the new differentiators that will define success in this evolving market.
For individuals aspiring to thrive in data science, ignoring these emerging requirements is no longer an option. The practical advice offered for acquiring each skill provides a clear roadmap for professional development. By proactively embracing these areas of expertise, data professionals can transform what might otherwise be a daunting skill gap into a powerful competitive advantage, ensuring they are not only prepared for the present but also equipped for the future of an increasingly sophisticated and AI-driven industry.














Leave a Reply