
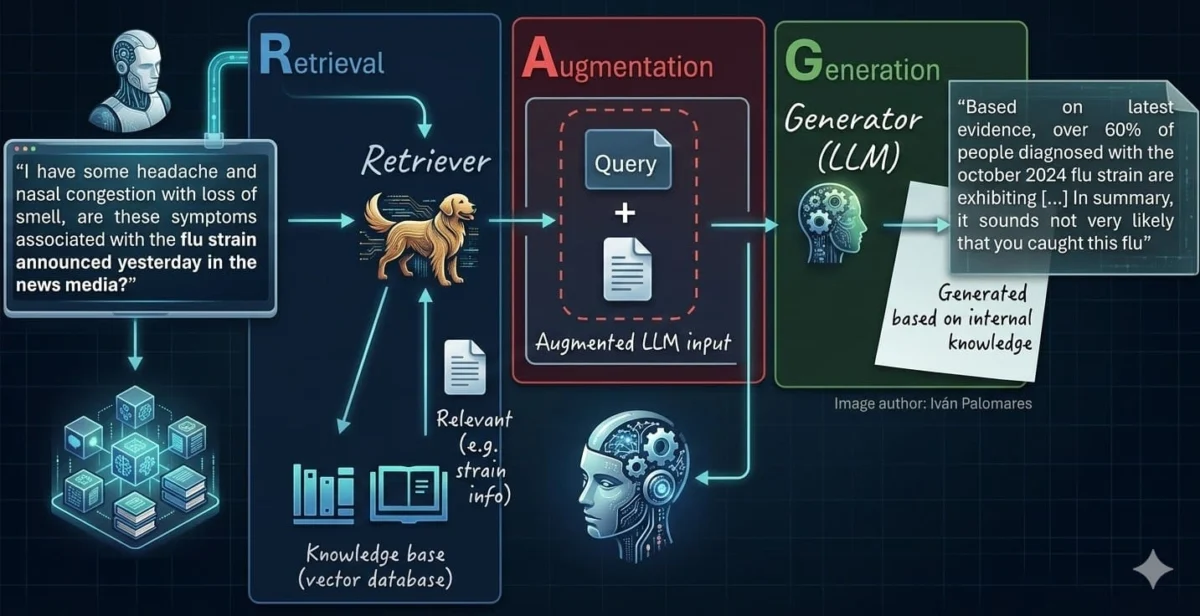
The evolution of artificial intelligence, particularly in the realm of natural language processing, has seen significant strides with the advent of large language models (LLMs). However, standalone LLMs frequently encounter limitations such as generating factually incorrect information (hallucinations), lacking up-to-date knowledge, or being unable to access domain-specific data crucial for enterprise applications. Retrieval-Augmented Generation (RAG) systems have emerged as a pivotal architectural pattern, representing the natural and necessary progression from these foundational LLMs, specifically designed to address these critical shortcomings by grounding responses in external, verifiable knowledge.
RAG systems function by integrating a retrieval mechanism with a generative LLM. When a user submits a query, the RAG system first retrieves relevant information from a designated knowledge base and then uses this retrieved context to inform the LLM’s generation process. This fusion significantly enhances the accuracy, relevance, and trustworthiness of the generated responses. Mastering the development of such systems involves a methodical approach, encompassing seven key stages, each vital for constructing a robust, high-performing RAG environment. These stages span from the initial data preparation to the final generation and evaluation of answers, forming a comprehensive framework for practitioners aiming to deploy sophisticated AI solutions.
The Genesis of RAG: Addressing LLM Limitations
The rapid proliferation of LLMs like GPT-3, PaLM, and Llama has revolutionized how humans interact with machines, offering unprecedented capabilities in understanding and generating human-like text. Yet, their reliance on static training data, often vast but finite, presents inherent challenges. LLMs can struggle with questions requiring real-time information, specialized domain knowledge, or precise factual recall beyond their training cutoff dates. More critically, they are prone to "hallucinations," producing confident but entirely fabricated answers, which severely limits their applicability in sensitive sectors like healthcare, legal, or finance where accuracy is paramount.
RAG was conceived to mitigate these issues by providing LLMs with an external, dynamic, and verifiable source of truth. By decoupling the knowledge acquisition from the generative process, RAG allows LLMs to access and integrate external documents, databases, or web content, ensuring responses are not only coherent but also factually grounded. This architectural shift has unlocked enterprise-grade performance, accuracy, and transparency, making LLM applications more reliable and knowledge-intensive, especially when dealing with proprietary organizational data. The following seven steps outline the essential processes for building and optimizing these transformative systems.
1. Selecting and Rigorously Cleaning Data Sources
The foundational principle of "garbage in, garbage out" holds maximum significance in RAG systems. The quality, relevance, and cleanliness of the source text data directly dictate the value and reliability of the knowledge base. Therefore, the initial step involves meticulous selection and preparation of data sources. Organizations must identify high-value data silos, which could range from internal company reports, technical manuals, customer support logs, research papers, legal documents, or curated web content. These sources should be periodically audited to ensure continued relevance and accuracy.
Before ingesting raw data, a robust data cleaning pipeline is indispensable. This process involves several critical steps:
- Removal of Personally Identifiable Information (PII): Essential for data privacy and regulatory compliance (e.g., GDPR, CCPA).
- Elimination of Duplicates: Redundant information inflates the knowledge base, introduces noise, and can skew retrieval results.
- Addressing Noisy Elements: This includes removing irrelevant boilerplate text, advertisements, broken HTML tags, special characters, or formatting inconsistencies.
- Normalization: Standardizing data formats, units, and terminology ensures consistency.
- Fact-Checking and Validation: For critical applications, incorporating mechanisms to verify factual accuracy where possible, or flagging unverified content.
- Handling Diverse Formats: Developing parsers for various document types (PDFs, Word documents, HTML, JSON, database entries) to extract clean, coherent text.
This is not a one-time task but a continuous engineering process, demanding ongoing maintenance and refinement as new data is incorporated and existing data evolves. Industry experts emphasize that investing heavily in this initial stage pays dividends throughout the RAG lifecycle, preventing costly downstream errors and enhancing overall system performance.
2. Intelligent Chunking and Splitting Documents for Context
Many source documents, such as extensive literature novels, legal contracts, or PhD theses, are too large to be effectively processed as single units by embedding models or to fit within the context window of LLMs. Chunking involves splitting these long texts into smaller, semantically coherent parts that retain contextual integrity. This requires a careful, strategic approach: chunks must not be too numerous, risking a loss of broader context, nor too few, as oversized chunks can dilute semantic search effectiveness and exceed LLM input limits.
Diverse chunking approaches exist, ranging from simple character count-based splits to more sophisticated methods driven by logical boundaries like paragraphs, sections, or even semantic markers. Modern frameworks like LlamaIndex and LangChain offer advanced splitting mechanisms that can:
- Recursive Character Text Splitting: A common method that attempts to split by a list of characters (e.g.,
nn,n,`,.` ) in order, trying to keep chunks as large as possible. - Context-Aware Chunking: Utilizing metadata or document structure (e.g., headings, subheadings) to ensure chunks represent complete ideas.
- Overlap Strategies: Incorporating a small degree of overlap between consecutive chunks helps preserve continuity and context during retrieval, especially when a query’s answer spans across chunk boundaries. For instance, a 10-20% overlap is a common practice.
- Hierarchical Chunking: Creating chunks at different granularities (e.g., entire document, sections, paragraphs) to enable multi-level retrieval.
Efficient chunking is also crucial for managing the context length of LLM inputs. By breaking down large documents into manageable segments, RAG systems can retrieve only the most relevant portions, optimizing token usage and reducing computational costs while maximizing the LLM’s ability to process the provided information effectively.
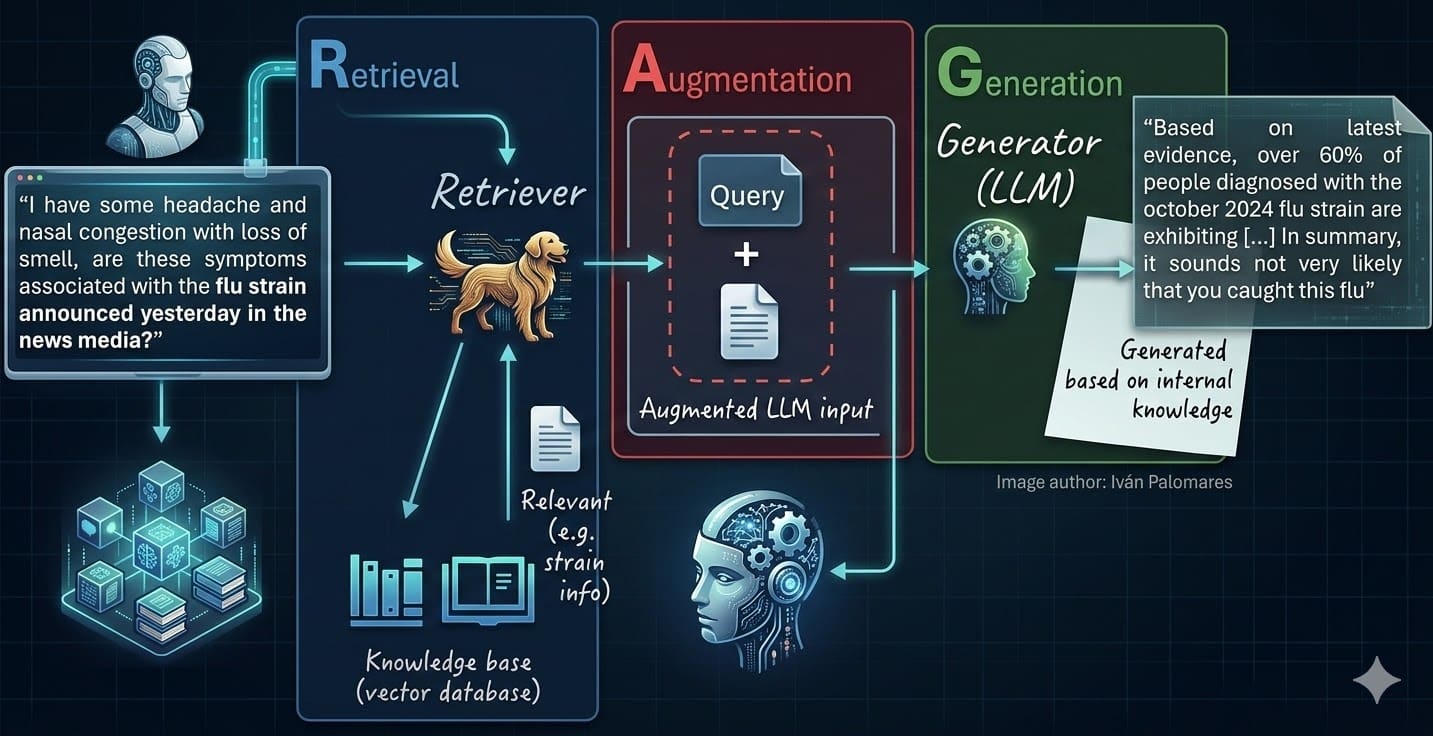
3. Embedding and Vectorizing Documents
Once documents are meticulously cleaned and appropriately chunked, the next crucial step is to translate them into a format machines can understand and process: numerical representations. This is achieved by converting each text chunk into a "vector embedding" – a dense, high-dimensional numeric array that captures the semantic characteristics of the text. These embeddings allow for mathematical comparisons, where semantically similar texts will have closely located vectors in the high-dimensional space.
The process relies on specialized LLMs known as embedding models. These models are trained to map text into a vector space such that the distance between vectors corresponds to their semantic relatedness. Popular open-source options include Hugging Face’s all-MiniLM-L6-v2, BAAI/bge-small-en-v1.5, or larger models like openai-ada-002. The choice of embedding model is critical and depends on factors such as:
- Performance: The accuracy with which it captures semantic similarity.
- Computational Cost: Inference speed and memory requirements.
- Domain Specificity: Some models perform better on general text, while others are fine-tuned for specific domains (e.g., scientific, legal).
- Multilinguality: Support for different languages if the knowledge base is multilingual.
Embeddings offer significant advantages over classical text representation approaches like TF-IDF or Bag-of-Words, which primarily focus on word frequency or co-occurrence without grasping deeper meaning. Embeddings encode context, synonyms, and relationships, enabling far more sophisticated and accurate semantic search.
4. Populating the Vector Database
With document chunks transformed into vector embeddings, the next stage involves storing them in a specialized infrastructure designed for efficient similarity search: the vector database (or vector store). Unlike traditional relational databases that are optimized for structured queries on tabular data, vector databases are engineered to handle high-dimensional vectors, enabling rapid nearest-neighbor searches. This is a critical component of RAG systems, as it facilitates the swift retrieval of relevant documents in response to user queries.
Vector databases leverage advanced indexing strategies, such as Approximate Nearest Neighbor (ANN) algorithms (e.g., HNSW, IVF_FLAT), to efficiently search through millions or billions of vectors. Key players in this burgeoning market include open-source solutions like FAISS (from Facebook AI Research) and Chroma, as well as freemium or commercial alternatives like Pinecone, Milvus, Weaviate, and Qdrant. These databases bridge the gap between human-readable text and their mathematical vector representations, providing features like:
- Scalability: Handling vast numbers of vectors and high query throughput.
- Low Latency: Delivering search results in milliseconds.
- Filtering Capabilities: Allowing pre-filtering of vectors based on metadata before similarity search, enhancing precision.
- Cloud-Native Architectures: Offering managed services and seamless integration with cloud ecosystems.
The integration of vector databases with RAG orchestration frameworks like LangChain is streamlined. The following Python code excerpt illustrates how text chunks can be embedded using a Hugging Face model and stored in a local Chroma vector database:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Assuming 'knowledge_base.txt' contains the long document
# Load and chunk the data
docs = TextLoader("knowledge_base.txt").load()
chunks = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50).split_documents(docs)
# Create text embeddings using a free open-source model and store in ChromaDB
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = Chroma.from_documents(documents=chunks, embedding=embedding_model, persist_directory="./db")
print(f"Successfully stored len(chunks) embedded chunks.")This code snippet demonstrates the practical steps of loading, chunking, embedding, and storing documents, forming the backbone of the RAG knowledge base.
5. Vectorizing User Queries
Just as the documents in the knowledge base are vectorized, user prompts expressed in natural language must undergo a similar transformation. A user’s query cannot be directly compared to the stored document vectors; it must first be translated into a numerical vector embedding. Crucially, this vectorization must be performed using the exact same embedding mechanism or model that was used to create the document embeddings (from step 3). This ensures consistency in the vector space, allowing for meaningful similarity comparisons.
Once the user’s query is vectorized into a single query vector, this vector becomes the basis for searching the knowledge base. This process is more than a simple translation; it represents the RAG system’s initial understanding of the user’s intent. Advanced approaches for query vectorization and optimization can further enhance retrieval quality:
- Query Expansion: Automatically adding synonyms, related terms, or rephrasing the query to broaden the search scope.
- Query Rewriting/Transformation: Using a smaller LLM to rewrite the user’s original query into multiple, more precise queries, or to extract key entities for structured search.
- Contextual Query Understanding: Incorporating conversational history or user profile data to refine the query vector for personalized or context-aware retrieval.
The goal is to generate a query vector that accurately reflects the user’s information need, maximizing the chances of retrieving highly relevant document chunks.
6. Retrieving Relevant Context
With the user’s query vectorized, the RAG system’s retriever component initiates a similarity-based search within the vector database to find the closest matching document chunks. This step is central to RAG’s ability to provide grounded answers. While traditional "top-k" approaches (retrieving the k most similar chunks) are common, advanced methods significantly optimize the relevance and quality of the retrieved context.
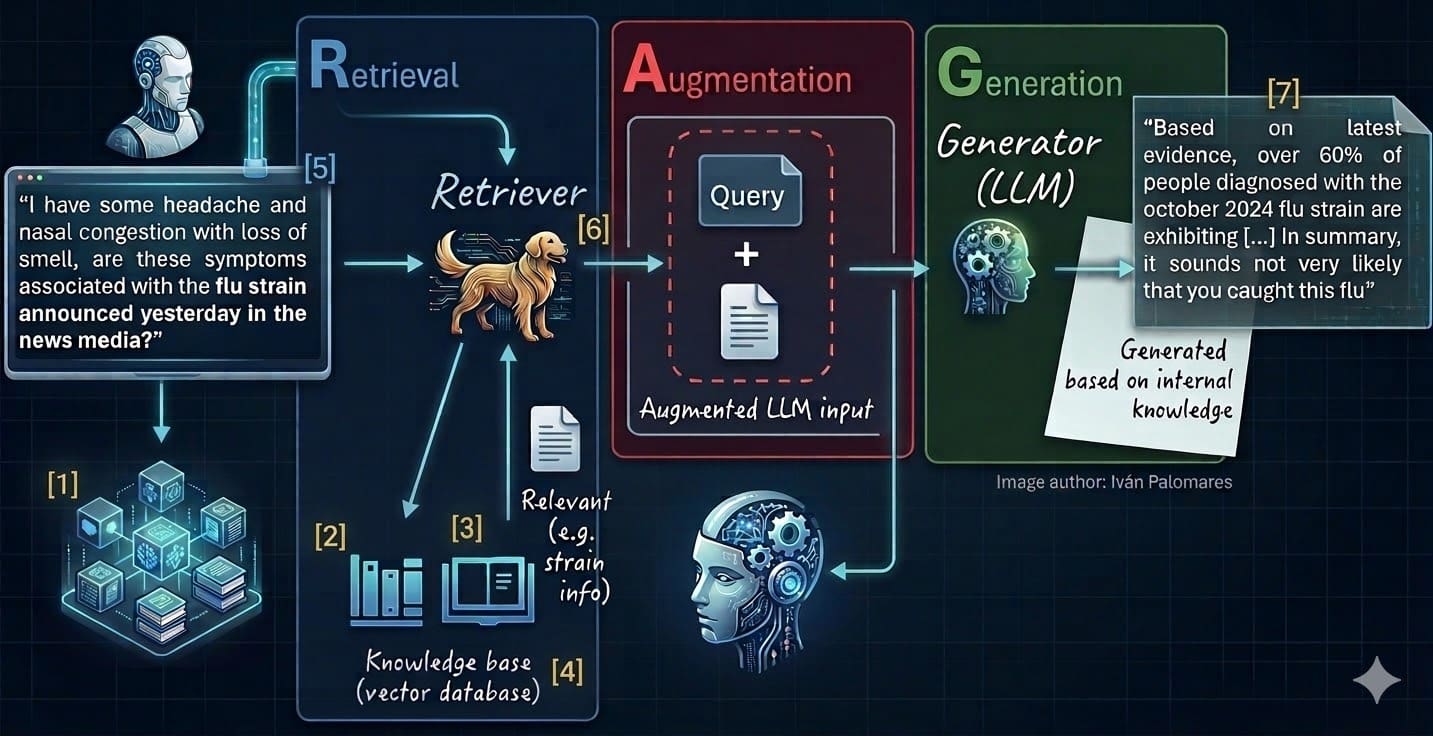
These advanced retrieval techniques include:
- Semantic Search: Leveraging the semantic properties of embeddings to find documents that are conceptually related, even if they don’t share exact keywords.
- Fusion Retrieval: Combining results from multiple retrieval methods (e.g., keyword search and semantic search) using techniques like Reciprocal Rank Fusion (RRF) to create a more comprehensive and robust set of initial candidates.
- Reranking: After an initial set of documents is retrieved, a separate, often smaller, reranker model is employed to re-score these documents based on a deeper understanding of the query and document content. This helps to filter out less relevant documents and prioritize the most pertinent ones, significantly improving precision.
- Multi-hop Retrieval: For complex queries requiring information synthesis from multiple sources or different parts of the knowledge base, the system might perform several iterative retrieval steps.
- Context Window Management: Efficient retrieval is paramount for managing the LLM’s context window. By providing only the most relevant and concise information, RAG systems prevent overfilling the LLM’s input, which can lead to information overload, reduced performance, and increased computational costs.
The effectiveness of this stage directly impacts the quality of the final generated answer. Continuous evaluation and fine-tuning of retrieval strategies are essential for optimizing RAG system performance.
7. Generating Grounded Answers and Evaluation
Finally, the Large Language Model enters the scene. It receives an "augmented" prompt that includes both the original user’s query and the carefully retrieved, highly relevant context. The LLM is then instructed to answer the user’s question using only the provided context. This crucial constraint is often embedded within the prompt engineering strategy (e.g., "Based on the following context, answer the question: [Context] Question: [Query]").
In a properly designed RAG architecture, meticulously following the preceding six steps, this process consistently leads to more accurate, defensible, and factually grounded responses. A significant advantage of RAG is the ability to include citations or direct references to the source documents within the generated answer, enhancing transparency and user trust. This attribution is particularly valuable in professional settings where verifying information is critical.
At this juncture, evaluating the quality of the generated response is paramount to measure the overall RAG system’s behavior. Dedicated evaluation frameworks, such as RAGAS, have been established to systematically assess various aspects of the generated answers, including:
- Faithfulness: How factually consistent the generated answer is with the retrieved context.
- Relevancy: How pertinent the answer is to the original query.
- Answer Correctness: The factual accuracy of the answer, often compared against a ground truth.
- Context Recall: How well the retrieved context covers all necessary information for the answer.
- Context Precision: How relevant the retrieved context is, without including distracting or irrelevant information.
These evaluations help signal when the underlying models or retrieval mechanisms may need refinement or even fine-tuning. While RAG reduces the need for extensive LLM fine-tuning, targeted fine-tuning of the generative LLM (e.g., to adjust its tone, style, or specific output format) can be considered after a robust RAG system is in place, further optimizing its performance for specific use cases.
Broader Impact and Strategic Implications
The mastery of Retrieval-Augmented Generation systems marks a significant leap in the practical application of Large Language Models, transcending their inherent limitations to deliver enterprise-grade performance. RAG architectures have become an almost indispensable aspect of modern LLM-based applications, with commercial and large-scale deployments rarely omitting them today.
Key Strategic Implications:
- Enhanced Reliability and Accuracy: RAG directly combats LLM hallucinations, providing verifiable and factually grounded responses, crucial for critical business operations.
- Access to Proprietary and Real-time Data: Organizations can leverage their internal, often sensitive, data without retraining or fine-tuning expensive LLMs, maintaining data privacy and intellectual property. This unlocks AI for highly specialized domains like legal research, medical diagnostics, or financial analysis.
- Cost-Effectiveness: RAG offers a more efficient alternative to continuous LLM fine-tuning or pre-training for new knowledge, as it only requires updating the knowledge base and re-indexing, rather than retraining the entire generative model.
- Transparency and Auditability: By providing citations to source documents, RAG systems improve the explainability and auditability of AI-generated content, fostering greater trust among users and stakeholders.
- Dynamic Knowledge: RAG systems can be updated with new information in near real-time by simply adding new documents to the vector database, keeping LLM applications current and relevant.
- Scalability and Flexibility: The modular nature of RAG allows for independent optimization of its components (retriever, generator, knowledge base), facilitating easier maintenance and upgrades.
By internalizing and meticulously implementing these seven essential steps, developers and organizations are positioned to construct enhanced LLM applications that unlock enterprise-grade performance, accuracy, and transparency. This capability represents a pivotal shift, moving beyond the capabilities of well-known public models to create intelligent solutions tailored precisely to specific organizational needs and data landscapes, ultimately driving innovation and competitive advantage in the AI-driven era.
Iván Palomares Carrascosa is a recognized leader, writer, speaker, and adviser in AI, machine learning, deep learning, and LLMs, dedicated to training and guiding others in harnessing artificial intelligence in real-world applications.














Leave a Reply