

The rapid ascent of large language models (LLMs) has revolutionized the landscape of artificial intelligence, promising unprecedented capabilities for automation, content generation, and intelligent interaction. However, the journey from a compelling prototype, meticulously crafted in a controlled development environment, to a robust, scalable, and secure production system is fraught with significant challenges. Many organizations encounter a critical chasm where their innovative LLM-powered features, initially fast and accurate in isolated testing, falter under the pressures of real-world deployment—experiencing performance degradation, escalating operational costs, and unexpected user interactions that expose vulnerabilities in reliability and safety.
This fundamental disconnect highlights that successful LLM integration into enterprise workflows extends far beyond mere model selection or prompt engineering. It necessitates a holistic approach encompassing architectural design, rigorous cost management, stringent safety protocols, and continuous performance monitoring. A recent industry survey indicated that while over 70% of businesses are experimenting with generative AI, less than 20% have successfully deployed these solutions at scale, often citing operational complexity and unmanaged costs as primary deterrents. This article outlines seven practical, strategic steps for organizations to navigate these complexities, transforming experimental LLM projects into resilient, production-grade AI systems capable of delivering sustained value.
Defining the Strategic Use Case with Precision
The bedrock of any successful LLM deployment is an unequivocally clear and well-defined use case. Ambiguity at this foundational stage invariably leads to misdirected efforts, over-engineered solutions, and a failure to meet actual business needs. A 2023 Gartner report highlighted that poorly defined project scope is a leading cause of AI project failures, impacting an estimated 40% of initiatives. Instead of broad directives like "develop an AI assistant," organizations must articulate precise objectives. For instance, differentiating between an LLM designed to answer internal HR FAQs, one for handling customer support tickets, or another for generating specific marketing copy dictates entirely different architectural considerations, model choices, and evaluation metrics.
Clarity extends to defining granular input and output expectations. What data formats will the system receive (e.g., free-form text, structured queries, multimodal inputs)? What format should the output take (e.g., natural language, structured JSON for downstream systems, code snippets)? These specifications are not merely technical details; they are critical design constraints that influence prompt engineering, the design of validation layers, and the user interface. Crucially, success metrics must be established upfront. Whether it’s response accuracy measured by F1-score, task completion rate, average latency, or user satisfaction scores (e.g., NPS), these quantifiable benchmarks provide a clear compass for development, optimization, and iteration. For example, a structured data extraction LLM, with its well-defined inputs and outputs, presents a significantly more manageable deployment challenge than a general-purpose conversational agent, underscoring the value of narrow, problem-centric definitions.

Selecting the Optimal Model: Beyond Raw Power
With a clear use case established, the subsequent critical decision revolves around model selection. The temptation to default to the largest, most powerful LLM available, often lauded in benchmarks, can be a costly misstep in a production environment. While larger models frequently demonstrate superior generalist capabilities, their operational overheads can quickly become prohibitive. Cost, often the primary constraint, scales directly with model size and inference volume. What might be an acceptable expenditure during prototype testing can escalate into a substantial operational expense with increased real-world traffic. Data from OpenAI suggests that API calls to their largest models can be several times more expensive than smaller variants, making judicious selection paramount for budget-conscious deployments.
Latency is another vital consideration, particularly for user-facing applications where even marginal delays can degrade user experience. Larger models inherently require more computational resources and time for inference, impacting responsiveness. Research indicates that users often abandon web interactions if load times exceed 2-3 seconds, a threshold easily breached by unoptimized large model inferences. While accuracy remains paramount, it must be contextualized: a smaller, fine-tuned model that performs exceptionally well on a specific task might be a more pragmatic choice than a larger, more generalized model that is slower and more expensive, yet only marginally more accurate for the specific application. The choice also involves weighing hosted APIs (e.g., OpenAI, Anthropic, Google Cloud AI) against self-hosting open-source models (e.g., Llama 2, Mistral). Hosted APIs offer ease of integration and reduced operational burden, trading off some control and data privacy. Open-source models provide greater flexibility, customization potential, and long-term cost control, but demand significant investment in infrastructure, MLOps expertise, and ongoing maintenance. The optimal model is therefore a confluence of use case fit, budget constraints, performance requirements, and strategic control.
Engineering a Robust System Architecture
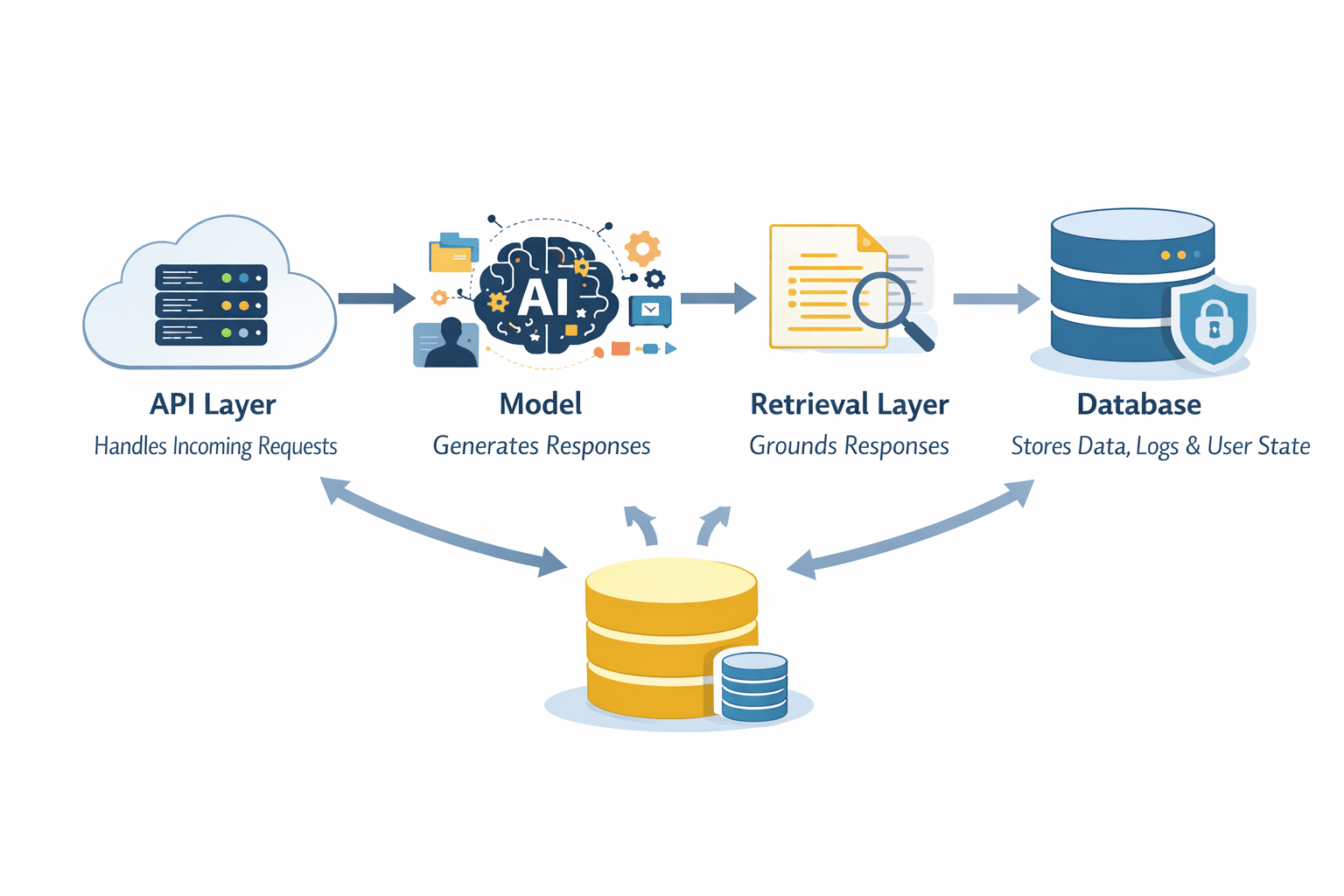
In a production setting, the LLM itself is merely one component within a sophisticated ecosystem. A typical enterprise-grade LLM system integrates multiple layers to ensure reliability, scalability, and maintainability. This architecture commonly comprises an API layer, the LLM for generation, a retrieval layer for contextual grounding, and persistent storage solutions such as databases. Each layer contributes uniquely to the system’s overall robustness.
The API layer serves as the crucial entry point, managing incoming requests, enforcing authentication and authorization, and intelligently routing inputs to appropriate backend components. This layer is instrumental for input validation, rate limiting, and ensuring secure access to the AI service. The LLM, while central, does not operate in isolation. Retrieval Augmented Generation (RAG) systems, for instance, leverage external data sources (e.g., vector databases, knowledge graphs) to fetch relevant context, significantly reducing model hallucinations and enhancing factual accuracy. This hybrid approach has become a cornerstone of enterprise LLM deployments, with studies showing RAG can improve factual consistency by over 30% in certain applications. Databases are essential for storing structured data, user interaction logs, conversation history for stateful applications, and system outputs that can be reused or analyzed. A key architectural decision lies in whether the system will be stateless (treating each request independently for easier scaling) or stateful (retaining context across interactions for a more personalized user experience, albeit with added complexity in data management). Adopting a pipeline-centric view, where input flows through validation, context enrichment, model processing, and post-processing before response, ensures each stage is controlled, observable, and optimizable. Microservices architectures, containerization (Docker, Kubernetes), and serverless functions are increasingly adopted to manage the complexity and scale of these multi-component systems, offering modularity and independent scalability.
Implementing Comprehensive Guardrails and Safety Layers
The raw output from even the most advanced LLMs should never be delivered directly to end-users without rigorous validation and safety checks. LLMs, despite their capabilities, are prone to generating incorrect, irrelevant, biased, or even harmful responses. Guardrails are indispensable mechanisms that mitigate these risks, upholding trust and preventing potential brand damage or legal liabilities.
These safety layers encompass a range of proactive and reactive measures. Input validation filters out malicious prompts (e.g., prompt injection attacks), personally identifiable information (PII), or irrelevant queries before they reach the model. Output filtering, conversely, scrutinizes model responses for undesirable content, such as hate speech, misinformation, or off-topic replies, leveraging content moderation APIs or custom classification models. Fact-checking mechanisms, often integrated with the retrieval layer, verify the veracity of generated statements against trusted knowledge bases. Additionally, sentiment analysis can detect and flag negative or aggressive tones, allowing for intervention or rephrasing. Ethical AI frameworks, such as those promoted by NIST or the EU AI Act, emphasize the need for transparency, fairness, and accountability, compelling organizations to build these guardrails into their deployment strategies. Without these layers, even a highly performant model can erode user trust and expose the organization to significant risks, transforming a powerful tool into a liability. A 2023 survey indicated that 68% of IT leaders are concerned about the security and compliance risks associated with generative AI, underscoring the urgency of robust guardrails.
Optimizing for Latency and Cost Efficiency
Once an LLM system is operational, its long-term viability hinges on efficient resource utilization and responsive performance. Suboptimal latency can lead to user frustration and abandonment, while unchecked costs can render a project economically unsustainable. Striking a balance between speed, quality, and expenditure is paramount.
Caching is a highly effective strategy for both latency and cost reduction. By storing and reusing responses to frequently asked or identical queries, organizations can significantly reduce the need for repeated model inferences, which are often the most expensive operations. This is particularly impactful for high-volume, repetitive interactions. Streaming responses, where output is delivered to the user incrementally as it’s generated, enhances perceived performance, making the interaction feel faster even if the total processing time remains constant. This psychological effect is crucial for user engagement. Dynamic model selection is another potent optimization technique. Not all requests demand the most powerful or expensive LLM. Simpler queries can be routed to smaller, more cost-effective models, while complex tasks are directed to more capable, albeit pricier, alternatives. This intelligent routing ensures resources are allocated appropriately based on task complexity. Batching, especially for non-interactive or background processes, aggregates multiple requests into a single inference call, improving throughput and reducing per-request overhead. Furthermore, techniques like model quantization (reducing precision of weights), pruning (removing less important connections), and distillation (training a smaller model to mimic a larger one) can significantly reduce model size and inference time without substantial accuracy loss, directly impacting both latency and computational costs, particularly for self-hosted models. Cloud cost management tools and FinOps practices become essential to monitor and optimize spending across various cloud resources.
Implementing Comprehensive Monitoring and Logging
Operating an LLM system without robust monitoring and logging is akin to navigating blindfolded. Visibility into the system’s operational health, performance, and user interactions is non-negotiable for stability and continuous improvement. Comprehensive logging forms the foundation, capturing every request and response, including user inputs, intermediate processing steps, and final model outputs. These detailed logs are invaluable for debugging, auditing, and understanding system behavior, especially when anomalies or errors occur.
Error tracking systems build upon logging, automatically surfacing failures such as timeouts, invalid outputs, or unexpected model behavior. Proactive alerting based on predefined thresholds ensures that issues are identified and addressed rapidly, preventing minor glitches from escalating into significant outages. Performance metrics, including average response time, throughput, error rates, and resource utilization (CPU, GPU, memory), provide a quantitative understanding of system efficiency and help pinpoint bottlenecks. Beyond technical metrics, monitoring model-specific performance indicators, such as hallucination rates or adherence to guardrails, is critical. User feedback, whether explicit ratings, thumbs-up/down signals, or implicit behavioral cues (e.g., rephrasing queries, abandoning conversations), adds a crucial qualitative dimension. This feedback helps bridge the gap between technical correctness and actual user satisfaction, revealing issues that purely technical metrics might miss. Implementing observability platforms (e.g., Datadog, Splunk, Grafana) and establishing clear service-level objectives (SLOs) and service-level indicators (SLIs) are industry best practices for maintaining a healthy and performant LLM system.
Iterating with Real User Feedback for Continuous Improvement
Deployment marks not the conclusion, but the commencement of the real work. No matter how meticulously designed, an LLM system will inevitably encounter unforeseen challenges and usage patterns once exposed to a diverse real-world user base. Users will push boundaries, provide messy inputs, and expose edge cases that eluded even the most thorough testing. Continuous iteration, driven by real user feedback, is therefore paramount for long-term success.
A/B testing is a powerful methodology for refining LLM systems in production. Organizations can deploy different prompt variations, model configurations, or architectural flows to distinct user segments, comparing their performance against predefined metrics. This data-driven approach replaces conjecture with empirical evidence, enabling informed decisions on optimizations. Prompt iteration continues in this phase, but it becomes grounded in actual usage data, addressing common failure modes and enhancing effectiveness. Similarly, the quality of retrieval systems, the efficacy of guardrails, and the intelligence of routing logic can all be incrementally improved based on observed user behavior and system performance. The most valuable input comes directly from user interactions: what they click, where they drop off, recurring queries, and explicit complaints. These behavioral signals offer profound insights into usability issues, unmet needs, and areas requiring refinement. This creates a virtuous feedback loop: users interact with the system, the system collects invaluable signals, and these signals, in turn, drive targeted improvements. This agile, iterative development cycle ensures the LLM system evolves in alignment with real-world demands, progressively enhancing its utility and reliability.
Conclusion
The journey to deploying enterprise-grade large language model systems is a multifaceted engineering and strategic endeavor, far more intricate than merely integrating an API or hosting a model. While the LLM itself is a powerful component, its effectiveness in a production environment is ultimately determined by the strength and coherence of the surrounding architecture, the robustness of its guardrails, the vigilance of its monitoring systems, and the agility of its iterative development process. The challenges—ranging from managing escalating costs and ensuring low latency to mitigating safety risks and adapting to unpredictable user behavior—underscore the need for a comprehensive, disciplined approach.
Successful LLM deployments prioritize reliability, ensuring consistent performance under varied conditions and scaling gracefully with increasing demand. They are designed for continuous improvement, leveraging real-world data and user feedback to evolve and refine their capabilities over time. This holistic perspective, which views the LLM as part of a larger, interconnected system, is what ultimately distinguishes fragile prototypes from resilient, high-impact AI solutions capable of delivering transformative value in the enterprise landscape. As the adoption of generative AI accelerates, mastering these deployment complexities will be a defining factor for organizations seeking to harness the full potential of this revolutionary technology.














Leave a Reply