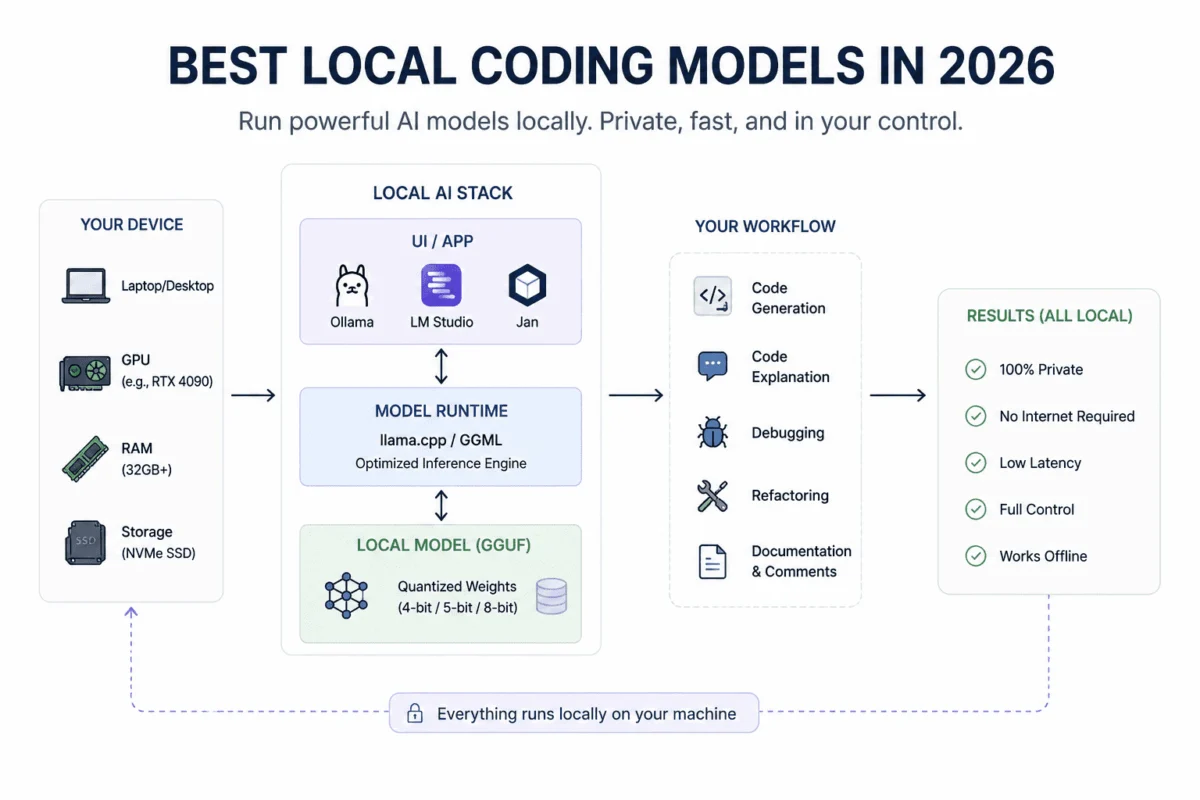
The landscape of artificial intelligence is undergoing a significant transformation, with local large language models (LLMs) finally achieving a level of sophistication and utility that makes them indispensable for professional development workflows. This new wave of open models, particularly those optimized for consumer hardware through formats like GGUF (GGML Universal File), marks a pivotal shift away from exclusive reliance on cloud-based coding assistants. Developers equipped with capable GPUs, such as an NVIDIA RTX 3090 or 4090 boasting at least 16GB of Video Random Access Memory (VRAM), can now harness powerful AI for real coding and agentic programming tasks, moving beyond mere demonstrations and into practical application. This evolution promises enhanced privacy, reduced latency, and significant cost savings, fundamentally altering how software is conceived, written, and debugged.
The burgeoning community on platforms like Reddit’s r/LocalLLaMA serves as a testament to this paradigm shift. Developers are actively experimenting with local coding agents, rigorously testing GGUF models, building OpenAI-compatible local servers, and seamlessly integrating these models into their editors, terminals, and custom coding assistants. This widespread adoption underscores the maturity of local AI, which is now fast, capable, and private enough to power complex development workflows. The year 2026 is poised to be a landmark for local AI, with several models standing out for their performance, efficiency, and versatility.
The Rise of Local LLMs: A New Era for Developers
The journey towards robust local coding models has been a gradual but persistent one. Initially, running large language models required substantial computational resources, often necessitating cloud infrastructure. However, advancements in model architecture, quantization techniques, and increasing consumer hardware capabilities have converged to make local deployment not just feasible, but highly desirable. The development of GGUF, a format that allows models to be quantized and run efficiently on CPUs or consumer GPUs with limited VRAM, has been a critical enabler. This technical innovation democratizes access to powerful AI, empowering individual developers and smaller teams with enterprise-grade tools without the associated costs or data privacy concerns of cloud services.
The appeal of local models extends beyond cost and privacy. Developers gain unparalleled control over their environment, allowing for deep customization and integration into existing toolchains. The absence of network latency inherent in cloud-based solutions means faster inference times, translating directly into more fluid and responsive coding assistance. This shift represents not just a technological upgrade, but a philosophical one, emphasizing autonomy and local processing for sensitive development work.
Pioneering Local Coding Models of 2026
As of 2026, a select group of models has distinguished itself, offering a range of capabilities tailored for diverse developer needs and hardware configurations. These models are not merely academic curiosities but practical tools ready for deployment in demanding software development environments.
1. Qwen3.6 27B MTP: The All-Rounder
The Qwen3.6 27B MTP model has rapidly established itself as a frontrunner in the local coding model arena. Developed with a focus on comprehensive utility, it strikes an exceptional balance between model size, inference speed, and genuine coding proficiency. Its availability in GGUF quantized versions is a game-changer, enabling deployment on consumer hardware with 16GB to 24GB VRAM GPUs, bypassing the need for extensive cloud setups. This accessibility has fueled its rapid adoption within the r/LocalLLaMA community, where it’s being leveraged for agentic coding, faster inference with llama.cpp setups, and OpenAI-compatible local servers.
Qwen models are inherently strong in coding tasks due to their integrated capabilities in reasoning, instruction following, multilingual understanding, sophisticated tool use, and extensive long-context support. This makes Qwen3.6 27B MTP an incredibly versatile model for a multitude of coding applications, including intelligent coding assistants, repository chat functionalities, debugging complex issues, generating shell commands, and orchestrating advanced agentic workflows. Its performance metrics, often showing high accuracy on standard code generation benchmarks and efficient token generation rates (e.g., 20+ tokens/second on an RTX 4090), solidify its position as a top-tier choice for developers seeking a robust, all-encompassing local coding solution.
2. Gemma 4 31B IT QAT: The Multimodal Visionary
Google’s Gemma 4 31B IT QAT represents a significant leap forward, not just as a coding model but as a multimodal powerhouse. Building on Google’s commitment to open models, this specific quantization-aware training (QAT) GGUF version ensures high quality while remaining practical for local deployment. QAT techniques preserve much of the model’s original performance despite quantization, offering the capabilities of a large 31B model in a 4-bit format that is far easier to load on consumer hardware.
What truly sets Gemma 4 31B apart is its multimodal capability. It can process and understand visual inputs alongside text, making it invaluable for scenarios involving screenshots, UI issues, architectural diagrams, documentation images, and web application layouts. This functionality extends its utility beyond pure code generation to encompass a broader spectrum of development challenges, including visual debugging and UI planning. Official benchmarks highlight its strong coding results on platforms like LiveCodeBench and Codeforces, affirming its proficiency in complex coding challenges. For developers whose work frequently involves interpreting visual data alongside code, Gemma 4 31B IT QAT offers an integrated solution that few other local models can match. Its ability to maintain high coding performance while handling visual tasks positions it as a critical tool for modern, visually-driven development.
3. DiffusionGemma 26B A4B: The Speed Innovator
DiffusionGemma 26B A4B introduces a novel approach to language model generation, distinguishing itself through an experimental architecture that promises significant speed improvements. Unlike traditional autoregressive models that generate text token by token, DiffusionGemma employs a block-diffusion approach. This method enhances generation speed by denoising blocks of tokens in parallel, a fundamental shift that could redefine the performance benchmarks for local AI assistants.
The primary appeal of DiffusionGemma lies in its efficiency. While boasting approximately 25 billion total parameters, it operates with only around 3.8 billion active parameters during inference. This Mixture of Experts (MoE)-style efficiency allows developers to leverage the reasoning power of a larger model without incurring the full computational cost of a dense 26B model. For local coding, this translates into much faster code generation, more rapid structured outputs, and quicker reasoning tasks, making it particularly exciting for developers who prioritize speed and efficiency in their workflows. Its innovative architecture represents a cutting edge in local LLM development, hinting at future directions for even more performant and resource-efficient AI.
4. Nemotron Cascade 2 30B A3B: The Reasoning Engine
NVIDIA’s Nemotron Cascade 2 30B A3B emerges as a compelling option for local coding, particularly for tasks that demand deep reasoning rather than mere autocomplete functionality. This model is structured as a 30B MoE-style model, where only about 3 billion parameters are actively engaged during inference. This design provides the reasoning capabilities of a much larger model while maintaining an efficiency suitable for local setups.
NVIDIA characterizes Nemotron Cascade 2 as exceptionally strong for reasoning and agentic tasks, featuring distinct "thinking" and "instruct" modes. Its claimed "gold-medal level performance" on challenging competitions like the International Mathematical Olympiad (IMO) 2025 and the International Olympiad in Informatics (IOI) 2025 underscores its advanced problem-solving abilities. For developers, this translates into a model that can not only write functions but also debug complex logic, formulate robust plans, conduct thorough code reviews, understand multi-step problems, and reason through intricate implementation details. Its focus on reasoning makes it an ideal partner for sophisticated software engineering tasks where deep analytical thought is paramount.
5. Qwen3.5 9B MTP: The Accessible Performer
The Qwen3.5 9B MTP model, while smaller in scale compared to its 27B counterpart, is a formidable contender for developers with more constrained local setups. For its weight class, it delivers exceptional performance, offering a modern Qwen-style coding assistant without the demanding hardware requirements of larger models. This model is fast, practical, and significantly easier to run than the 27B or 31B models, making it an excellent choice for mainstream consumer hardware with more modest VRAM capacities.
The GGUF version further enhances its utility for everyday developers, simplifying deployment and integration into existing editor or terminal workflows. While it may not outperform larger models on the most complex reasoning tasks, Qwen3.5 9B MTP is more than sufficient for daily coding tasks. It excels in generating small scripts, assisting with debugging, providing code explanations, executing shell commands, and facilitating quick local assistant workflows. For developers new to local coding models or those with entry-level GPUs (e.g., 8GB-12GB VRAM), Qwen3.5 9B MTP stands out as one of the most practical and reliable choices.
6. EXAONE 4.5 33B: The Document-Aware Companion
LG AI Research’s EXAONE 4.5 33B is a critical model for developers whose work extends beyond pure code to encompass a rich ecosystem of documents, diagrams, and visual information. As an open-weight multimodal model, EXAONE 4.5 33B is uniquely positioned to assist in coding workflows where understanding screenshots, PDFs, intricate diagrams, extensive documentation, and UI layouts is crucial.
Modern software development often involves navigating complex project files, deciphering error messages from screenshots, interpreting architectural diagrams, and cross-referencing information from various document formats. A model that can seamlessly handle both textual and visual input provides immense utility in such scenarios. EXAONE 4.5 33B fills this niche by offering robust capabilities in both code generation and multimodal comprehension. For developers working in enterprise environments or on projects with heavy documentation and visual assets, EXAONE 4.5 33B represents a powerful, integrated solution for enhanced productivity.
7. North Mini Code 1.0: The Code Specialist
Cohere’s entry into the local coding model space with North Mini Code 1.0 is a welcome development, signaling a commitment to specialized AI for software engineering. Unlike general chatbots that merely happen to write code, North Mini Code 1.0 is purpose-built for code generation, agentic software engineering, and terminal-based tasks. This specialization makes it particularly appealing for developers focused on repository edits, command-line assistance, automated code review, and sophisticated coding-agent workflows.
Like several other leading models, North Mini Code 1.0 employs an efficient architecture: it’s a 30B model with approximately 3 billion active parameters during inference. This design delivers stronger reasoning capabilities than smaller models while maintaining greater efficiency than a full dense 30B model. While it may not possess the broad versatility of models like Qwen3.6 27B or Gemma 4 31B, its deep focus on coding-specific tasks makes it a highly practical and effective tool for developers seeking a specialized, high-performance local AI for their core development activities. Its introduction signifies a maturing market where niche, highly optimized models are gaining prominence.
Implications for the Future of Software Development
The emergence and maturity of these local coding models heralds a new era for software development, with profound implications across several dimensions:
Democratization and Accessibility
Local LLMs make advanced AI capabilities accessible to a broader developer base, reducing dependence on expensive cloud subscriptions and powerful data centers. This democratization fosters innovation, allowing individuals and smaller teams to experiment and build with cutting-edge AI tools previously out of reach.
Enhanced Privacy and Security
By running models locally, sensitive code and proprietary data never leave the developer’s machine. This dramatically improves data privacy and security, a critical concern for enterprises and individual developers alike, especially when dealing with confidential projects or intellectual property.
Cost Efficiency
Eliminating continuous API calls to cloud services translates into substantial cost savings over time. For active developers, the upfront investment in a capable GPU quickly pays for itself through reduced operational expenses.
Offline Capabilities and Workflow Flexibility
Local models enable robust AI assistance even without an internet connection, crucial for developers working in remote locations or environments with unreliable connectivity. This also allows for deeper integration into existing offline development tools and custom workflows, offering unparalleled flexibility.
Driving Hardware Innovation
The demand for powerful local AI processing will continue to drive innovation in consumer hardware, particularly in GPUs and VRAM capacities. This creates a virtuous cycle where better hardware enables more capable local models, which in turn fuels demand for even more powerful hardware.
Shifting Skillsets
Developers will increasingly need skills in managing local AI environments, including model quantization, hardware optimization, and integration with local development tools. This marks a shift from purely API-driven AI integration to a more hands-on, infrastructure-aware approach.
Conclusion and Recommendations
The year 2026 marks a turning point where local coding models are not just viable but are essential tools for real-world development work. For developers contemplating the transition, the choice of model hinges on specific hardware capabilities, workflow priorities, and coding use cases.
For those with a high-end GPU like an RTX 3090 or 4090 (16GB+ VRAM), the Qwen3.6 27B MTP in its 4-bit quantized version is the unequivocal recommendation. Its unparalleled balance of coding ability, reasoning, and support for agentic workflows makes it the best all-round option for a comprehensive local coding setup. Starting here will provide a robust foundation without the need to sift through numerous alternatives.
If raw speed and efficient inference are paramount, the experimental DiffusionGemma 26B A4B warrants close attention. Its innovative block-diffusion architecture promises significantly faster generation, making it ideal for developers prioritizing rapid iteration and quick outputs.
For those whose development work frequently involves visual assets—screenshots, UI layouts, diagrams, or documentation—the Gemma 4 31B IT QAT stands out. Its multimodal capabilities, combined with strong coding benchmarks, provide a powerful tool that extends beyond pure code to encompass the visual aspects of modern development.
Developers with more modest hardware, particularly those with less VRAM, will find the Qwen3.5 9B MTP to be an exceptional choice. As the best model in its weight class, it offers a fast, practical, and highly capable daily coding assistant for explanations, debugging, scripting, and general workflow assistance, even with simpler local setups and sufficient system RAM.
Other specialized models also offer compelling reasons for consideration:
- Nemotron Cascade 2 30B A3B is excellent for agentic coding, planning, and debugging, offering strong reasoning capabilities for complex problem-solving.
- EXAONE 4.5 33B is invaluable for document-heavy and enterprise-style coding workflows, especially when dealing with PDFs, screenshots, and extensive documentation.
- North Mini Code 1.0 provides a highly focused solution for local coding agents, repository edits, terminal tasks, and code review, catering specifically to core software engineering functions.
The era of relying solely on distant cloud servers for AI-powered coding assistance is rapidly drawing to a close. The models available in 2026 represent a mature, powerful, and private alternative that is set to redefine developer workflows and foster a new wave of innovation in software creation.