

The reliability of artificial intelligence, particularly large language models (LLMs), hinges significantly on their ability to accurately express confidence in their outputs. A fundamental principle in machine learning dictates that a model stating 90% confidence should, in fact, be correct 90% of the time. When this crucial relationship falters, a state of "miscalibration" emerges, rendering the model’s confidence scores unreliable and potentially misleading. This issue has become increasingly prevalent with the widespread adoption of LLMs across diverse applications, prompting a concentrated effort within the AI community to develop robust calibration techniques.
The Pervasive Problem of Miscalibration in LLMs
Miscalibration is not merely an academic curiosity; it poses tangible risks in real-world deployments where LLMs are used for critical tasks such as medical diagnostics, financial forecasting, legal advice, or code generation. An overconfident LLM could lead to erroneous decisions being made without adequate human oversight, while an underconfident one might unnecessarily trigger human intervention, negating the efficiency gains AI promises.
Recent research underscores the depth of this challenge. A comprehensive 2024 NAACL survey highlighted that confidence scores generated by LLMs frequently diverge from their actual correctness rates across a spectrum of tasks, including factual question-answering, complex code generation, and intricate reasoning problems. This indicates a systemic issue rather than isolated incidents. Further corroborating these findings, another study focusing on biomedical models, published in bioRxiv in early 2025, revealed alarmingly low mean calibration scores, ranging from a mere 23.9% to 46.6% across all models tested. This consistent gap between perceived and actual accuracy points to a significant hurdle in achieving truly trustworthy AI systems. The problem is not confined to specific domains or model architectures; it appears to be an intrinsic characteristic that requires dedicated solutions.

Historically, the machine learning community has addressed such issues through post-hoc recalibration. This involves fitting a simple function on a held-out validation set to map raw confidence scores to more accurate, better-calibrated probabilities. These methods, primarily developed for discriminative classifiers, have served as the cornerstone of improving model trustworthiness for decades. Three techniques have dominated this space: temperature scaling, Platt scaling, and isotonic regression. However, the unique architectural and operational characteristics of LLMs introduce significant complexities when attempting to apply these established methods, necessitating careful adaptation and novel approaches.
Measuring Trustworthiness: Metrics and Diagrams
To effectively tackle miscalibration, it is imperative to have precise tools for its measurement. The dominant metric in this field is the Expected Calibration Error (ECE). ECE quantifies miscalibration by grouping predictions into confidence bins, calculating the disparity between the mean confidence and the observed accuracy within each bin, and then averaging these differences, weighted by the size of each bin. A perfectly calibrated model would yield an ECE of 0.
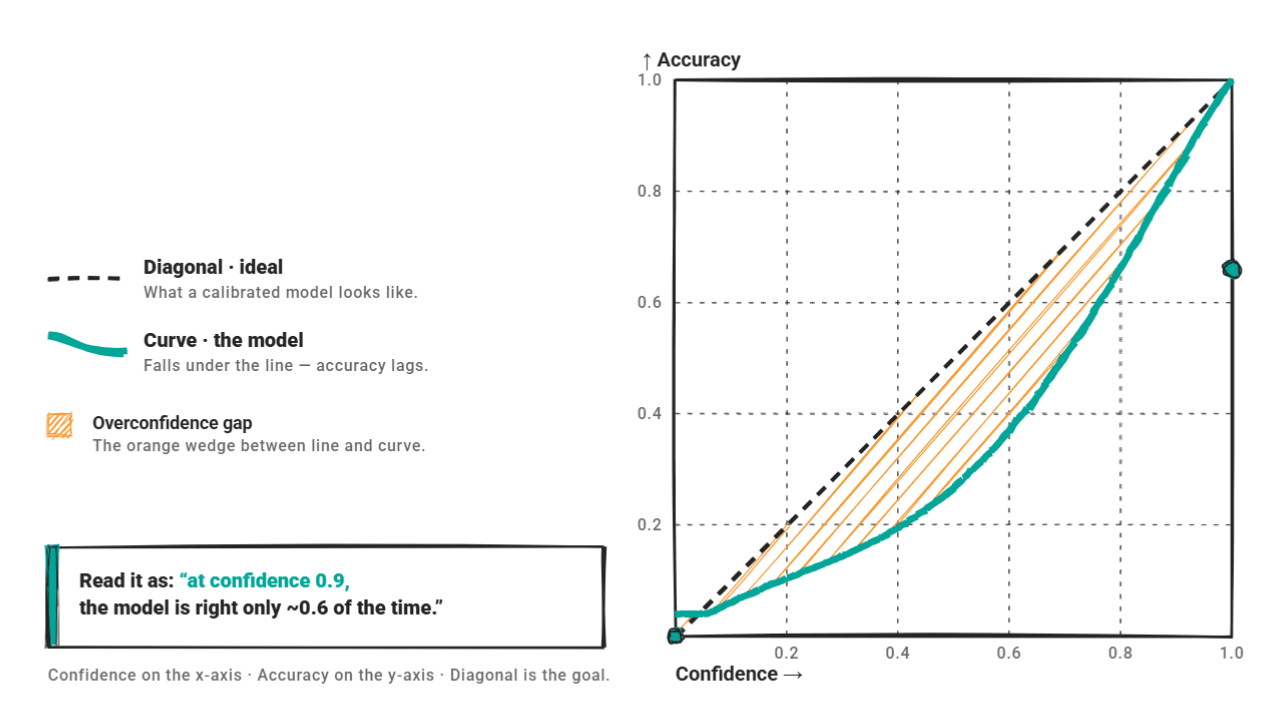
Beyond a single numerical metric, reliability diagrams offer a powerful visual representation of a model’s calibration. In such a diagram, confidence is plotted against accuracy. An ideal, perfectly calibrated model’s performance would align precisely with the diagonal line, indicating that its stated confidence perfectly matches its correctness. Conversely, an overconfident model’s curve would fall below the diagonal, signaling that its high confidence claims are not met by equivalent accuracy levels. This visual insight is crucial for understanding where and how a model misbehaves. For instance, a 2025 evaluation of GPT-4o-mini functioning as a text classifier reported that a staggering 66.7% of its errors occurred at over 80% confidence, a canonical example of pronounced overconfidence.
While ECE provides a convenient summary statistic, a growing consensus among researchers views it as insufficient on its own. A research paper published in late 2025 (arXiv:2512.16030) strongly advocates for a multi-metric approach, recommending the pairing of ECE with the Brier score (a proper scoring rule that measures the accuracy of probabilistic predictions), overconfidence rates, and reliability diagrams. This holistic approach helps to mitigate the risk that a single aggregated number might obscure meaningful variations in a model’s calibration behavior, providing a more comprehensive understanding of its strengths and weaknesses.

Classical Solutions: A Foundation for LLM Trustworthiness
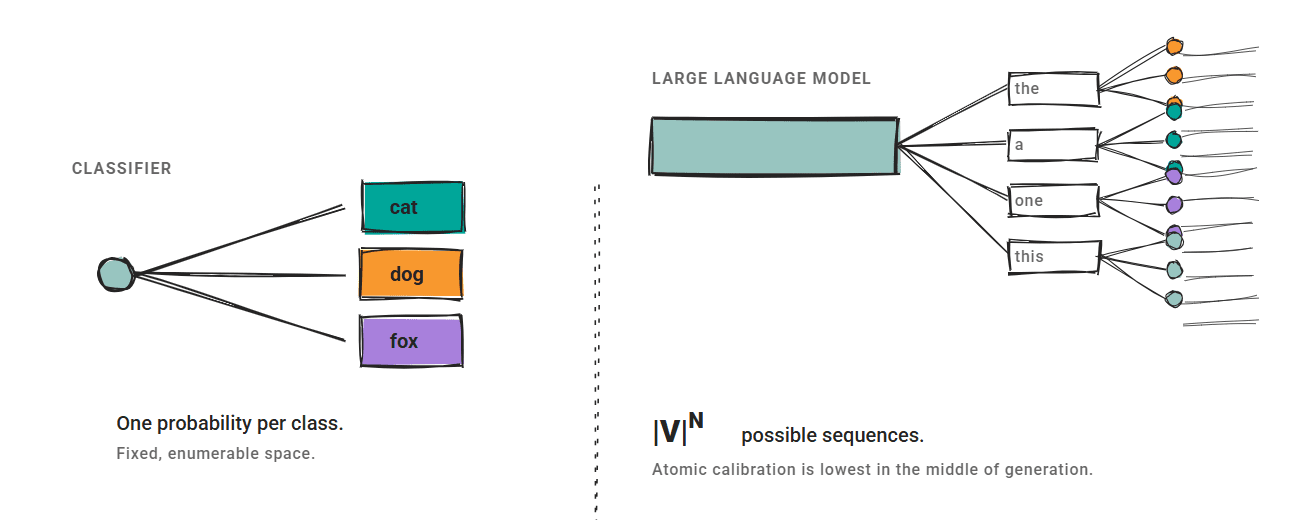
The traditional calibration methods—temperature scaling, Platt scaling, and isotonic regression—were primarily designed for classical machine learning classifiers, which operate with a fixed, often small, output space (e.g., classifying an image into one of 10 categories). A classifier typically outputs a single probability for each class, and calibration aims to adjust these probabilities to be more accurate estimates of true correctness.
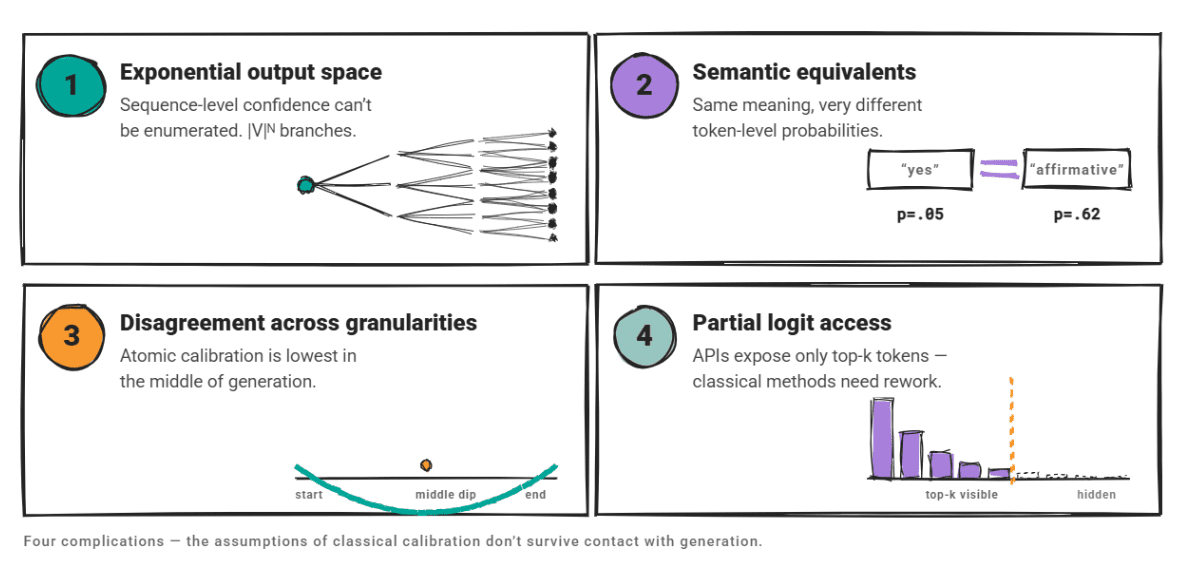
However, LLMs present a vastly different paradigm. Their generative nature means their output space is exponentially large, comprising sequences of tokens rather than a finite set of classes. This fundamental difference introduces several complications for applying classical calibration techniques directly. Sequence-level confidence cannot be easily enumerated or directly mapped in the same way as a fixed set of class probabilities. Moreover, semantically equivalent outputs from an LLM might be generated with vastly different token-level probabilities, making the aggregation of confidence scores challenging. Confidence can also fluctuate significantly across different granularities; a 2024 NAACL paper on "atomic calibration" found that generative models often exhibit their lowest average confidence in the middle of a generation process, rather than at its beginning or end.
A further practical hurdle arises from the common practice of accessing LLMs via APIs, which often expose only top-k token probabilities rather than full logit access. This limitation restricts the direct application of some classical calibration approaches that rely on comprehensive logit information. These complexities necessitate a nuanced approach to adapting traditional methods for the unique characteristics of LLMs.
Temperature Scaling: Adapting to LLM Nuances
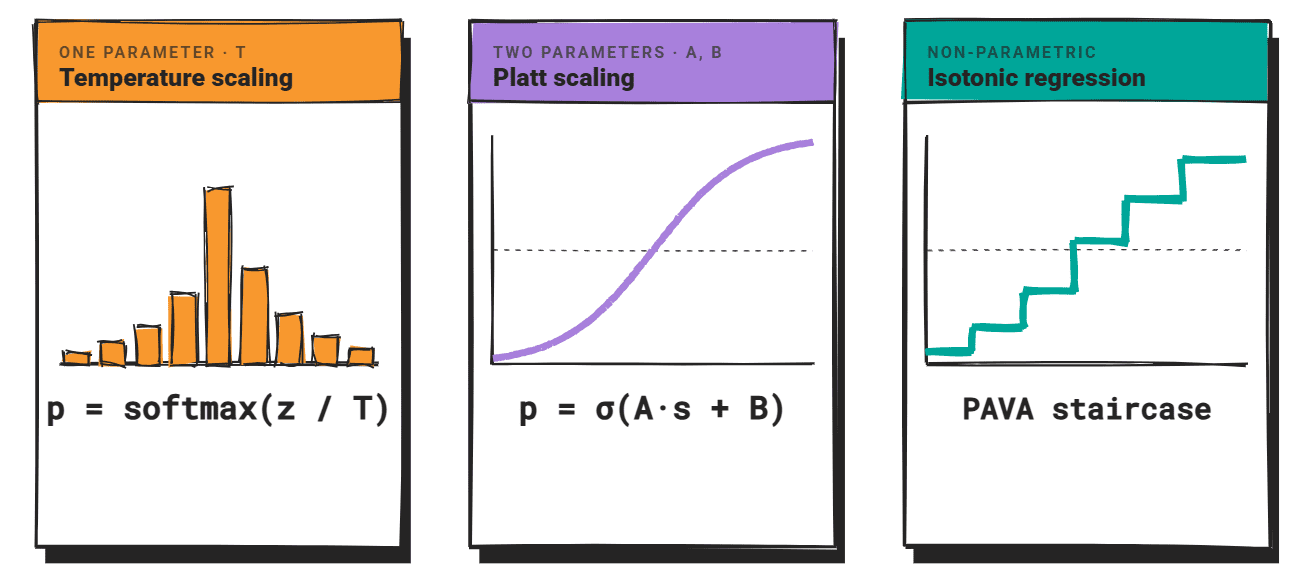
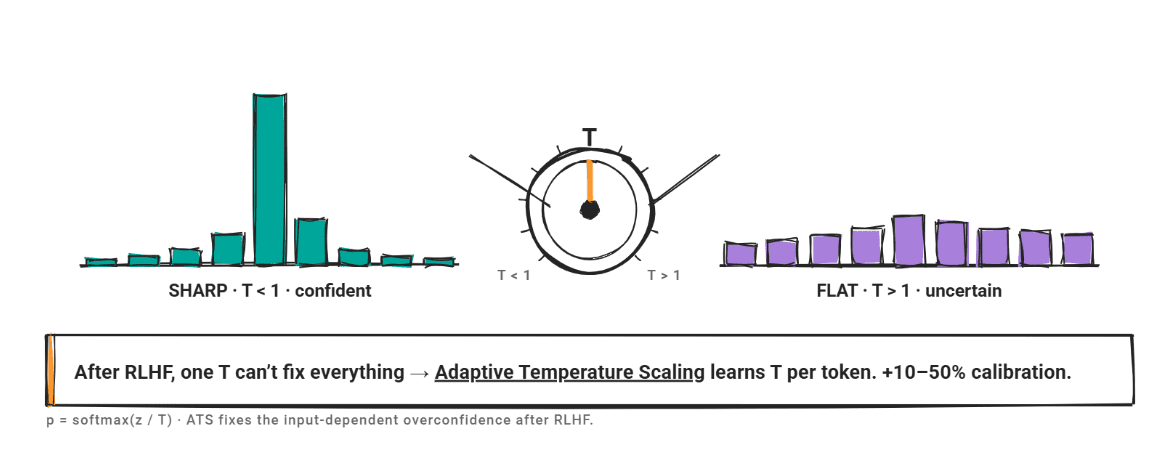
Temperature scaling is one of the most widely adopted and simplest post-hoc calibration methods. It operates by dividing the logit vector (the raw, unnormalized outputs from the model before the softmax function) by a scalar value, T, before applying softmax to convert them into probabilities. When T is greater than 1, the probability distribution over the vocabulary flattens, effectively reducing the model’s confidence. Conversely, when T is less than 1, the distribution sharpens, increasing confidence.
The optimal value for T is determined by minimizing the negative log-likelihood on a held-out validation set. This method is computationally inexpensive, adds only one parameter to the model, and critically, preserves the ranking of predictions—meaning the model’s top choice remains the top choice, just with a better-calibrated probability. The original formulation targeted DenseNet image classifiers, but its core logic extends well to LLMs, where temperature can control the probability distribution over the vocabulary at each decoding step.
However, a significant complication arises with models that have undergone Reinforcement Learning from Human Feedback (RLHF). RLHF is a powerful fine-tuning technique that aligns LLMs with human preferences and instructions, often leading to impressive performance gains and more human-like responses. A documented side effect of this process is the development of input-dependent overconfidence. This means the degree of miscalibration can vary significantly across different inputs, making a single, global temperature (T) insufficient to correct all variations. Average ECE scores exceeding 0.377 have been observed for RLHF-tuned models like GPT-3 in tasks requiring verbalized confidence, and a comprehensive 2025 survey (arXiv:2505.18658v2) confirmed that RLHF-tuned models consistently overestimate confidence across a broad range of benchmarks.
To address this challenge, Adaptive Temperature Scaling (ATS) was introduced. Instead of a single fixed T, ATS predicts a per-token temperature directly from token-level hidden features, which are then fit on a supervised fine-tuning dataset. Researchers have demonstrated that ATS can improve calibration by 10-50% without negatively impacting the model’s primary task performance. For any LLM that has undergone RLHF, ATS emerges as a significantly stronger baseline than standard temperature scaling. Nevertheless, for base models that have not yet undergone RLHF, where miscalibration tends to be more uniform across inputs, a single, global temperature T often proves sufficient to correct systematic over- or underconfidence. The specificity of ATS highlights the evolving nature of calibration research in response to advancements in LLM training paradigms.
Platt Scaling: Efficiency and Specificity
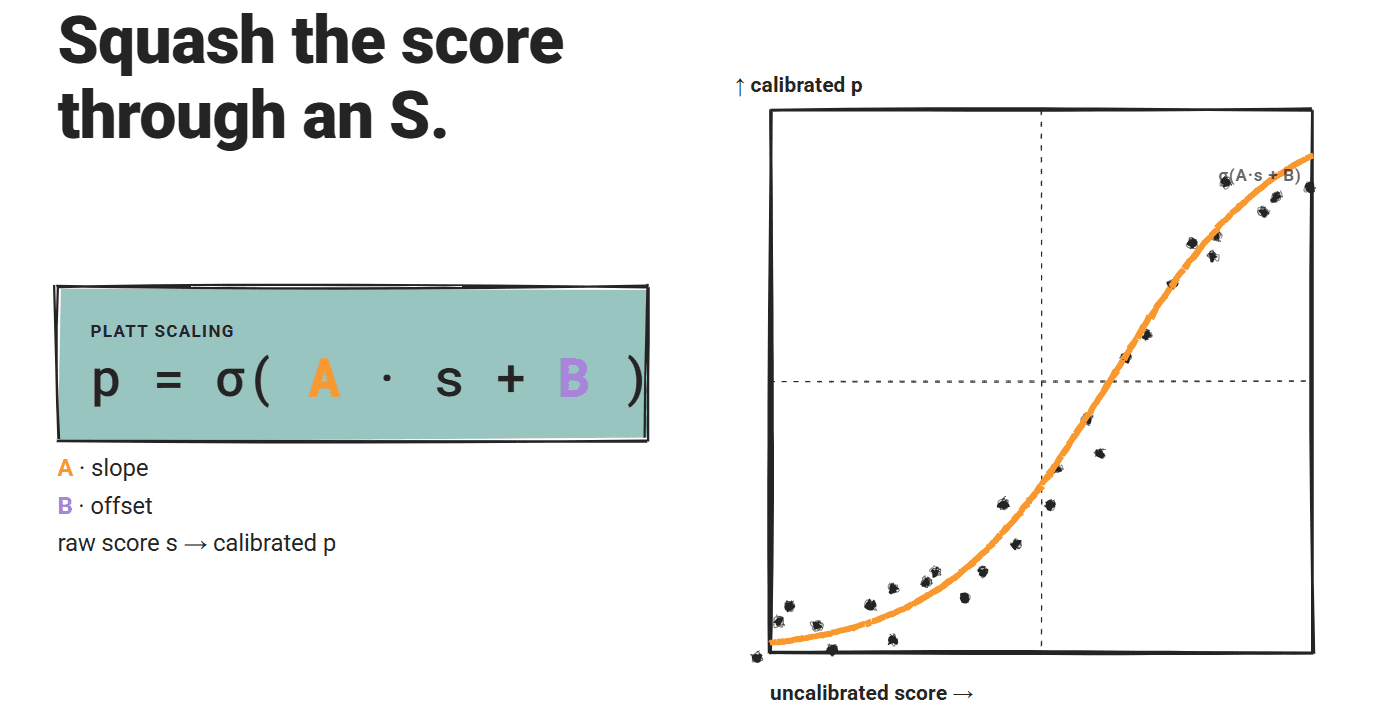
Platt scaling offers another parametric approach to post-hoc calibration. Originally developed to calibrate the outputs of Support Vector Machines (SVMs), it fits a logistic (sigmoid) function over the uncalibrated scores. The mathematical form is typically expressed as p = σ(A * s + B), where ‘s’ represents the uncalibrated confidence score, ‘σ’ is the sigmoid function, and ‘A’ and ‘B’ are two parameters learned from a held-out validation set using binary correctness labels.
The sigmoid shape provides a flexible yet constrained parametric mapping with only two free parameters. This parsimonious design makes Platt scaling data-efficient; it can often produce usable calibration estimates from a relatively smaller calibration dataset compared to more complex non-parametric methods. This efficiency is a critical advantage in deployment contexts where acquiring large volumes of precisely labeled correctness data can be expensive and time-consuming.
In the context of LLMs, Platt scaling can be applied to either sequence-level or token-level confidence scores. A paper presented at ICSE 2025 focusing on LLM-generated code confidence demonstrated that Platt scaling yielded better-calibrated outputs than raw, uncalibrated scores. Expanding on this, a study on LLMs used for text-to-SQL tasks introduced Multivariate Platt Scaling (MPS). MPS extends the single-variable Platt scaling by combining sub-clause frequency scores across multiple generated samples, consistently outperforming single-score baselines. This innovation showcases how classical methods can be adapted and extended to handle the multi-faceted outputs of LLMs.
Despite its advantages, Platt scaling has documented limitations. Firstly, applying global sequence-level Platt scaling can be too coarse for tasks where correctness hinges on localized edit decisions within a generated sequence. A single sigmoid mapping struggles to capture miscalibration patterns that vary significantly across different parts of a generated output or across different samples. Secondly, for already strong, well-performing models, Platt scaling can sometimes degrade proper scoring performance (metrics like the Brier score), indicating that its assumptions might not always align with the intricacies of highly performant systems.
Isotonic Regression: The Non-Parametric Powerhouse
Isotonic regression represents a non-parametric alternative to temperature and Platt scaling. Instead of assuming a specific functional form (like a linear scaling or a sigmoid curve), it learns a piecewise-constant, monotonically non-decreasing mapping from the uncalibrated scores to calibrated probabilities. This is typically achieved using the Pool Adjacent Violators Algorithm (PAVA). The primary strength of isotonic regression lies in its flexibility: it makes no assumptions about the underlying shape of the confidence-accuracy relationship, allowing it to adapt to linear, stepped, concave, or any other monotone shape. This adaptability is often cited as the main reason why isotonic regression frequently outperforms Platt scaling in empirical comparisons, particularly when the true relationship is complex.
The cost of this flexibility is a higher risk of overfitting, especially when working with small calibration datasets. The learned mapping only generalizes well when there is sufficient data to constrain its shape accurately. Empirically, when sufficient data is available, isotonic regression consistently demonstrates superior performance. A rigorous 2025 comparison study (arXiv:2509.23665v1) across multiple datasets and architectures found that isotonic regression statistically significantly outperformed Platt scaling on both ECE and Brier score, employing paired t-tests with Bonferroni correction at α = 0.003. In one instance, a Random Forest baseline improved its reliability score from 0.8268 (uncalibrated) to 0.9551 with Platt scaling, and further to 0.9660 with isotonic regression. While both methods could, in some cases, degrade proper scoring performance for exceptionally strong models, the consistent edge of isotonic regression was maintained.
For LLM multiclass settings, researchers have further shown that standard isotonic regression can be enhanced through normalization-aware extensions, consistently outperforming both One-vs-Rest (OvR) isotonic regression and standard parametric methods on metrics like negative log-likelihood (NLL) and ECE. However, the data requirement remains the binding constraint. The empirical advantages of isotonic regression are well-established, but its practical applicability is often limited to scenarios where a sufficiently large and representative calibration set is available. In low-data deployment scenarios, its performance gains might diminish or even reverse due to overfitting.
Navigating the Uncharted Waters: Gaps and Future Research
Despite significant progress, several critical gaps remain in the application and understanding of these calibration methods for LLMs, particularly concerning their real-world deployment.
The interaction with Reinforcement Learning from Human Feedback (RLHF) has primarily been studied in the context of temperature scaling, leading to the development of Adaptive Temperature Scaling (ATS). However, how Platt scaling and isotonic regression perform on post-RLHF models has not been systematically tested. Given that RLHF can induce input-dependent overconfidence, it is an open question whether these other methods require similar extensions or adaptations to maintain their effectiveness in such complex, fine-tuned models. The absence of this understanding represents a significant blind spot for developers working with state-of-the-art LLMs.
Furthermore, most direct comparisons of all three methods originate from the general machine learning calibration literature, which often focuses on classical discriminative models. LLM-specific benchmarks that rigorously test all three head-to-head across a diverse range of generative tasks are still rare. The ICSE 2025 code calibration paper is one of the few examples, but its scope is limited to code generation. A broader comparative analysis is needed to establish definitive best practices for LLM calibration.
Finally, the impact of calibration set size is a critical, often understated, deployment constraint. The impressive results for isotonic regression cited in academic papers often assume the availability of large datasets, sufficient to robustly constrain its non-parametric mapping. In real-world production environments, where labeled correctness data is frequently scarce and expensive to obtain, the empirical gap between isotonic regression and Platt scaling may significantly narrow or even reverse. Practical guidelines for selecting the optimal method based on the available calibration data size are crucial for practitioners.
Real-World Implications and the Path Forward
The effective calibration of LLMs is not merely a technical optimization; it is a foundational requirement for building trustworthy and responsible AI systems. In high-stakes domains, uncalibrated LLMs could inadvertently propagate misinformation, compromise safety, or lead to biased outcomes. For instance, in medical applications, an LLM generating diagnostic suggestions with unwarranted high confidence could lead clinicians to overlook critical details. In financial advisory, overconfident predictions could result in poor investment decisions.
For development teams and organizations deploying LLMs, the choice of calibration method is a strategic one, dependent on the specific model, task, and available resources. For base models that have not undergone RLHF, standard temperature scaling often serves as an excellent starting point, providing sufficient correction for systematic miscalibration with minimal computational overhead. When working with RLHF-tuned models, switching to Adaptive Temperature Scaling (ATS) is highly recommended, as its per-token temperature approach effectively addresses the input-dependent overconfidence that a global scalar cannot.
Platt scaling stands out as a practical and data-efficient choice, particularly when the calibration set is small or when calibration needs to be seamlessly integrated into a larger, resource-constrained pipeline. Its simplicity and two-parameter fit make it straightforward to implement. However, its limitation in capturing sample-dependent miscalibration patterns and its potential to degrade performance for already strong models must be considered.
Isotonic regression, with its strongest empirical track record, should be the preferred method when a sufficiently large calibration set is available to train its non-parametric mapping without overfitting. In multiclass settings, pairing it with normalization-aware extensions can further enhance its performance. This method offers the most precise calibration when its data requirements can be met.
The Foundational Question: Defining "Confidence"
Ultimately, the decision that precedes the selection of any calibration method is the definition of "confidence" itself for the specific task at hand. LLMs can generate various forms of confidence signals: token probability, sequence probability, verbalized confidence (where the model explicitly states its certainty in natural language), or consistency across multiple generated samples. These different interpretations can yield vastly different values for the "confidence" associated with the same output.
A calibration method, however sophisticated, applied to the wrong signal will not genuinely improve reliability. For example, calibrating token-level probabilities may not translate to accurate sequence-level confidence, especially if the generation process involves complex interdependencies between tokens. Similarly, verbalized confidence, while intuitive for human users, can be prone to the model’s inherent biases and "hallucinations" if not carefully handled. Getting this foundational definition right—understanding precisely what "confidence" means for a given LLM application—is the indispensable prerequisite for any of these sophisticated calibration methods to work effectively and contribute to building truly trustworthy and dependable artificial intelligence systems. As LLMs become more integrated into societal infrastructure, ensuring their stated confidence aligns with their actual accuracy will be paramount for fostering public trust and enabling responsible innovation.













