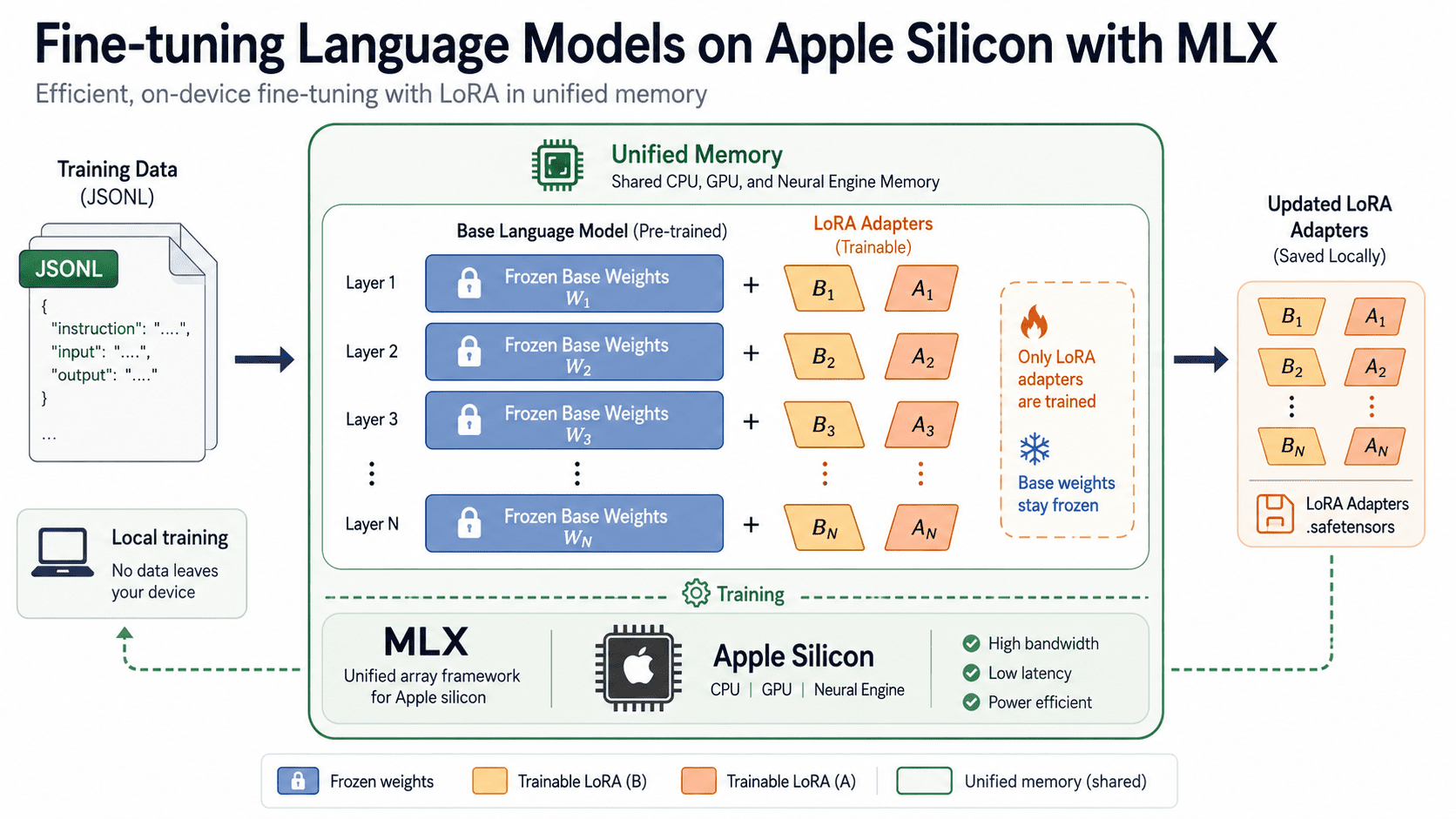
The landscape of artificial intelligence development, once heavily reliant on expensive cloud-based graphics processing units (GPUs), is undergoing a significant transformation. A new era has dawned for developers, particularly those leveraging Apple’s proprietary Silicon chips, where the intricate process of fine-tuning large language models (LLMs) can now be performed entirely on-device, eliminating cloud computing costs and bolstering data privacy. This capability is powered by MLX, an open-source array library meticulously crafted by Apple’s machine learning research team specifically for its unified memory architecture, coupled with its companion package, MLX LM.
This shift represents a profound departure from the traditional paradigm, where adapting open models to proprietary datasets typically involved renting high-end GPUs from cloud providers like AWS, Google Cloud, or Azure, incurring substantial operational expenses. For Mac users equipped with an Apple Silicon chip (M1, M2, M3 series, or newer), the ability to perform such complex tasks locally, at zero cloud cost, is not merely a convenience but a fundamental re-democratization of advanced AI development. The integration of hardware and software, a hallmark of Apple’s design philosophy for over a decade, is now yielding unprecedented dividends in the realm of on-device machine learning, allowing for the complete lifecycle of model adaptation without a single byte of data ever leaving the local machine.
The Genesis of Local AI: From Cloud Dependency to On-Device Empowerment
Historically, the development and deployment of sophisticated AI models, especially LLMs, have been bottlenecked by immense computational requirements. Training and fine-tuning these models demand vast parallel processing capabilities, traditionally provided by NVIDIA’s high-performance GPUs, such as the A100 or H100, often accessed through cloud services. This reliance on the cloud presented several challenges: exorbitant costs, particularly for extended training sessions; latency issues associated with data transfer to and from remote servers; and, critically, significant data privacy and security concerns, as sensitive proprietary data had to be uploaded to third-party infrastructure.
The early 2020s witnessed a surge in the accessibility of open-source LLMs, championed by organizations like Hugging Face, which provided pre-trained models such as Llama, Mistral, and GPT-2/3 variants. This move democratized access to powerful models but did little to alleviate the computational burden of customizing them. Innovations in model compression and quantization techniques, like GPTQ and GGML/GGUF, began to emerge, enabling inference of larger models on more constrained hardware. However, fine-tuning, which involves adapting a pre-trained model to specific tasks or datasets, remained largely a cloud-bound endeavor due to the demanding nature of gradient calculations and weight updates.
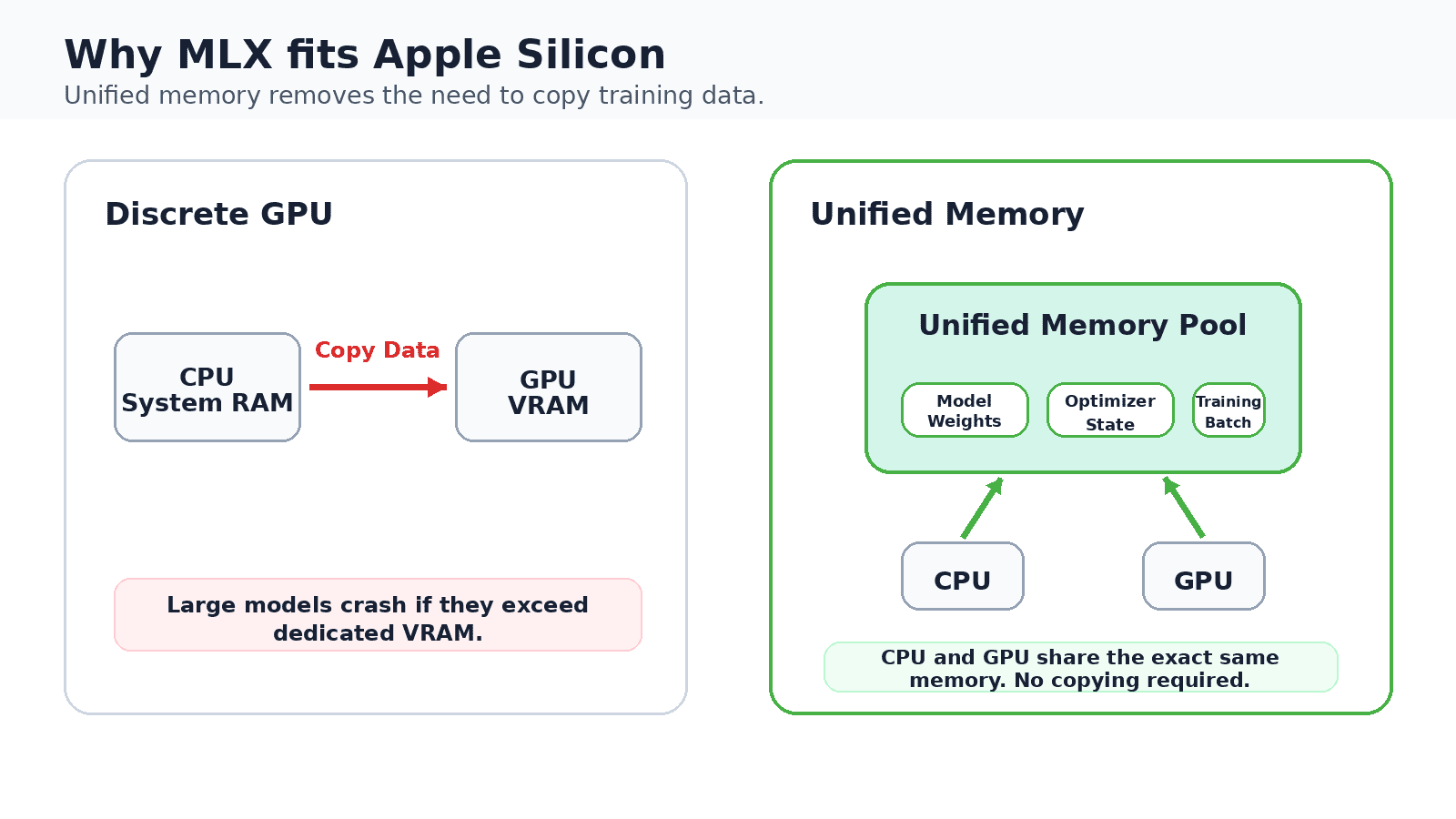
Apple’s entry into this space with its custom-designed Silicon chips marked a pivotal moment. Introduced with the M1 chip in late 2020, Apple Silicon redefined performance per watt in consumer and professional computing. Beyond raw speed, the architectural innovation of unified memory proved to be a game-changer for machine learning. Unlike traditional systems where the CPU and GPU have separate, dedicated memory pools, Apple Silicon integrates them into a single, high-bandwidth memory architecture. This eliminates the time-consuming and energy-intensive data copying steps that typically shuttle information between system RAM and GPU VRAM, a critical bottleneck in deep learning workloads. On a 16 GB Apple Silicon Mac, model weights, optimizer states, and training batches can all coexist in the same memory space, making local fine-tuning not just feasible, but highly efficient.
MLX: Apple’s Native Framework for the Unified Memory Era
The introduction of MLX directly addresses the unique capabilities of Apple Silicon. While many local inference tools were initially developed for NVIDIA hardware and subsequently ported, often with compromises, to macOS, MLX was conceived from the ground up for Apple’s unified memory architecture. This bespoke design ensures optimal performance and resource utilization, fully leveraging the tight integration between hardware and software that has been Apple’s strategic advantage. The MLX API, with its close resemblance to NumPy, offers familiarity to a broad range of data scientists and developers, while integrating automatic differentiation for training and utilizing Apple’s Metal framework for accelerated GPU operations.
MLX LM, the complementary package, extends MLX’s capabilities by providing streamlined text generation and fine-tuning functionalities for thousands of open models. This pairing allows developers to perform complex tasks, from installing the necessary tools and preparing datasets to training LoRA (Low-Rank Adaptation) adapters, quantizing models for reduced memory footprint, and finally, testing and serving the fine-tuned results—all through a concise set of commands.
For developers keen to harness this technology, the prerequisites are straightforward: an Apple Silicon Mac (M1 or newer), macOS Ventura 13.5 or later, and Python 3.10 or above. Intel-based Macs are explicitly not supported, underscoring MLX’s deep architectural ties to Apple Silicon. This specificity ensures that the framework delivers on its promise of unparalleled local ML performance.
Setting Up the Environment: A Seamless Entry Point
Initiating the MLX environment is designed for simplicity. A single pip install "mlx-lm[train]" command fetches the core package and its necessary training dependencies. Verification of the installation is equally straightforward, involving a quick generation test with a pre-quantized Mistral model. For instance, executing mlx_lm.generate --model mlx-community/Mistral-7B-Instruct-v0.3-4bit --prompt "Explain LoRA in two sentences." --max-tokens 120 not only confirms the setup but also demonstrates the framework’s ability to download and cache models from the MLX Community organization on Hugging Face, which hosts a vast array of pre-converted models ready for immediate use.
A crucial point for developers is MLX’s requirement for models in the Hugging Face safetensors format for fine-tuning. While GGUF files, prevalent in other local LLM tools, are compatible for inference, they are not supported for training within MLX LM. However, the framework boasts broad support for popular open-source architectures, including Llama, Mistral, Qwen2, Phi, Gemma, and Mixtral, ensuring that most widely used models are accessible out-of-the-box. This focus on standard and efficient formats streamlines the fine-tuning workflow significantly.
Preparing Datasets for Bespoke Model Adaptation
The success of any fine-tuning endeavor hinges on the quality and structure of the training data. MLX LM expects training data to be organized into a folder containing three JSONL (JSON Lines) files: train.jsonl (mandatory), valid.jsonl (optional, for reporting validation loss during training), and test.jsonl (optional, for post-training evaluation). Each line within these files represents a single JSON example.
MLX LM supports three primary data formats:
- Chat format: The most robust option, storing role-tagged messages per line, allowing the model’s native chat template to be applied for conversational consistency. Example:
"messages": ["role": "user", "content": "What is LoRA?", "role": "assistant", "content": "An efficient way to fine-tune a model."]. - Completions format: Simpler for instruction-style tasks, providing plain input-output pairs. Example:
"prompt": "Summarize: The market rose sharply today.", "completion": "Markets gained.". - Text format: For unstructured text data.
A key feature for optimizing training is the --mask-prompt flag. By default, the trainer computes loss over the entire example, meaning the model learns to reproduce both the prompt and the desired response. When --mask-prompt is enabled, loss computation is restricted to the completion alone, directing the training effort more effectively towards generating relevant responses and improving instruction following. This is particularly beneficial for chat data, where the final message in a conversation is treated as the completion.
Best practices for dataset preparation include ensuring each example resides on a single line without internal line breaks, as the reader processes each line as a distinct record. Data splitting typically involves allocating approximately 80% to train.jsonl and 10-20% to valid.jsonl. For meaningful behavioral changes in a model, a sensible minimum of 200 to 500 examples is recommended; fewer examples risk overfitting, where the model memorizes rather than generalizes.
Training LoRA Adapters: Efficiency and Precision
The core of efficient fine-tuning on MLX lies in Low-Rank Adaptation (LoRA), a technique that revolutionized the adaptation of large models. Instead of updating every single weight in a massive pre-trained model, LoRA freezes the original weights and introduces small, trainable adapter matrices (A and B) alongside them. These adapters are then trained, significantly reducing the number of parameters that need updates. This method, introduced in the 2021 paper by Hu et al., drastically cuts down memory and storage requirements to a mere fraction of what full fine-tuning would demand, while largely preserving the model’s quality and performance.
Launching a LoRA training run is executed via a single command, specifying the base model and the data folder:
mlx_lm.lora --model mlx-community/Mistral-7B-Instruct-v0.3-4bit --train --data ./data --iters 600 --batch-size 1
During training, MLX LM provides real-time feedback, displaying training loss, validation loss, processed tokens, and iterations per second. The trained adapter weights are saved to an adapters folder by default. Developers have several critical flags at their disposal to customize the training process:
--fine-tune-type: Acceptslora(the default),dora(Denoising-Optimized Low-Rank Adaptation), orfullfor comprehensive fine-tuning.--num-layers: Determines how many transformer layers receive adapters (default: 16).--iters: Controls the total number of training iterations.--batch-size: Crucially, setting--batch-size 1is often recommended for 16 GB Macs to minimize memory consumption and prevent crashes. For machines with 64 GB or more, increasing this to 2 or 4 can accelerate training.--grad-accumulation-steps: Allows for a larger effective batch size without a corresponding increase in memory usage, smoothing out gradients.--report-to wandb: Integrates with Weights & Biases for live graph visualization of metrics.--num-layersand--grad-checkpoint: These are vital for memory optimization. Reducing--num-layersto 8 or 4, or enabling--grad-checkpoint(which trades computation for lower memory footprint), can often resolve out-of-memory issues.
Strategic Model and Adapter Configuration
Two fundamental decisions profoundly influence the outcome of a fine-tuning project: the choice of the base model and the configuration of the adapter. For initial projects, an 8-billion parameter (8B) model in its 4-bit quantized form represents an ideal balance of performance and resource efficiency. As developers gain familiarity, scaling up to 13B or 14B models is feasible on machines with 32 GB of unified memory, typically requiring 14 to 18 GB of working memory.
The capacity of the LoRA adapter is governed by the number of trained layers and the adapter’s rank. A greater number of layers and a higher rank afford the adapter more learning capacity but demand more memory and training time. A common starting point is 16 layers with a moderate rank, with adjustments made based on observing validation loss. If training loss continues to fall while validation loss begins to climb, it’s a strong indicator of overfitting, suggesting the adapter is memorizing the training examples rather than generalizing.
The learning rate is another critical hyperparameter. Values typically ranging from 1e-5 to 5e-5 are effective for most LoRA runs. A learning rate that is too high can lead to unstable training, while one that is too low may result in minimal model updates. Iterative experimentation, changing one setting at a time, is key to attributing improvements to specific choices.
QLoRA: Quantization as a Memory Multiplier
The mention of a base model ending in 4bit highlights the inherent support for QLoRA (Quantized Low-Rank Adaptation) within MLX. QLoRA, detailed in the 2023 QLoRA paper, combines LoRA with 4-bit quantization of the base model weights. This synergy dramatically reduces the memory footprint of the entire fine-tuning process. A 4-bit quantized 7B model can cut weight memory by approximately 3.5 times compared to its full-precision counterpart, making it comfortably finetunable within 8 GB of working memory. On a 16 GB MacBook, this leaves ample headroom for the operating system and the training batch, a feat previously unimaginable for local consumer hardware.
MLX integrates quantization seamlessly; the same mlx_lm.lora command can train adapters directly on quantized weights without any additional setup. For developers who prefer to manually quantize a full-precision model, the mlx_lm.convert command provides this utility:
mlx_lm.convert --hf-path mistralai/Mistral-7B-Instruct-v0.3 --mlx-path ./mistral-4bit -q
This command generates a 4-bit quantized version of the model in a local folder, which can then be specified as the --model for subsequent training.
Testing, Generation, and Deployment: Completing the Workflow
Upon completion of training, evaluating the adapter’s performance is crucial. The mlx_lm.lora --test command can score the model against a held-out test set, providing a quantifiable metric for tracking progress across experiments. To observe the model’s responses in action, the same adapter path can be passed to the mlx_lm.generate command:
mlx_lm.generate --model mlx-community/Mistral-7B-Instruct-v0.3-4bit --adapter-path ./adapters --prompt "Summarize: Our quarterly revenue grew twelve percent."
Comparing responses with and without the adapter quickly demonstrates the effectiveness of the fine-tuning. If the dataset was well-matched to the target task, the adapted responses should exhibit a closer alignment with the training examples than the base model.
For deployment, where a single, self-contained model is often preferred over a base model plus an adapter, the mlx_lm.fuse command merges the adapter weights back into the base model:
mlx_lm.fuse --model mlx-community/Mistral-7B-Instruct-v0.3-4bit --adapter-path ./adapters --save-path ./fused-model
The resulting fused model behaves identically to any other MLX model and can be served through an OpenAI-compatible endpoint using mlx_lm.server --model ./fused-model --port 8080. This allows existing client applications to interact with the locally fine-tuned model with minimal configuration changes. For a more user-friendly graphical interface, LM Studio offers a one-click local server and chat interface, enabling side-by-side comparisons of fine-tuned models.
Broader Implications: Democratization, Privacy, and Innovation
The emergence of MLX on Apple Silicon transcends mere technical advancement; it heralds a new era for AI development with far-reaching implications.
Democratization of AI: The most significant impact is the dramatic lowering of the barrier to entry for customizing LLMs. No longer is advanced model adaptation the exclusive domain of large enterprises with multi-million dollar cloud budgets. Independent developers, startups, small businesses, and academic researchers can now iterate on and deploy highly specialized AI models with consumer-grade hardware, fostering an unprecedented wave of innovation. This levels the playing field, making cutting-edge AI accessible to a much broader community.
Enhanced Data Privacy and Security: The ability to perform the entire fine-tuning workflow on-device offers a robust solution for data privacy. For sectors handling highly sensitive information, such as healthcare, finance, legal, or government, keeping proprietary data entirely within the local environment eliminates the risks associated with uploading to third-party cloud servers. This on-device processing ensures that confidential data remains under the user’s direct control, adhering to strict compliance regulations and mitigating potential breaches.
Cost Efficiency: The elimination of cloud GPU rental fees translates into substantial cost savings for developers. Cloud GPU instances, particularly those with the computational power required for LLM fine-tuning, can cost hundreds or even thousands of dollars per month, or per specific project, depending on usage. By shifting these workloads to local Apple Silicon Macs, developers can achieve comparable results at a fraction of the cost, making advanced AI development economically viable for a much wider audience.
Energy Efficiency: Apple Silicon chips are renowned for their exceptional power efficiency. Performing ML tasks locally on these chips consumes significantly less energy compared to running equivalent workloads in large, energy-intensive cloud data centers. This contributes to a more sustainable AI development ecosystem, aligning with growing environmental consciousness.
Fostering Localized AI Innovation: The ease of local fine-tuning encourages the creation of highly specialized, niche AI applications tailored to specific user needs or datasets. This could lead to a proliferation of domain-specific LLMs, optimized for particular industries, languages, or tasks, driving innovation in areas previously underserved by generic large models.
Competitive Landscape: This development positions Apple as a formidable player in the AI ecosystem, not just as a hardware manufacturer but as a platform enabler for advanced AI development. While NVIDIA continues to dominate the high-end cloud GPU market, Apple’s strategy carves out a powerful niche in on-device AI, potentially shifting developer preferences and investments towards its integrated ecosystem.
The Future Outlook: As Apple continues to advance its Silicon architecture with future generations (M4, M5, and beyond), the capabilities for on-device machine learning are only expected to grow. This trajectory suggests a future where sophisticated AI models are not only fine-tuned locally but also run predominantly on edge devices, enabling faster, more private, and more personalized AI experiences.
Conclusion
The integration of MLX with Apple Silicon represents a landmark achievement in the journey towards democratizing AI. It provides a comprehensive, cost-effective, and privacy-centric workflow for fine-tuning language models, bringing powerful machine learning capabilities directly to the developer’s desktop. The author’s personal journey, starting with a switch to Mac in 2014, aptly underscores how Apple’s enduring commitment to hardware-software integration has culminated in a platform uniquely capable of serious machine learning work, accessible from a home office or kitchen table.
Developers are now empowered to explore new horizons: experimenting with dora fine-tuning for comparative analysis, optimizing num-layers and iteration counts for desired quality-speed trade-offs, and readily swapping in different base architectures like Llama, Qwen, Phi, or Gemma. Each experiment is now economically inexpensive, removing a significant barrier to iterative development and fostering a vibrant, accessible ecosystem for adapting language models. This paradigm shift fundamentally alters how developers approach AI, ushering in an era of personalized, private, and powerful on-device machine learning.