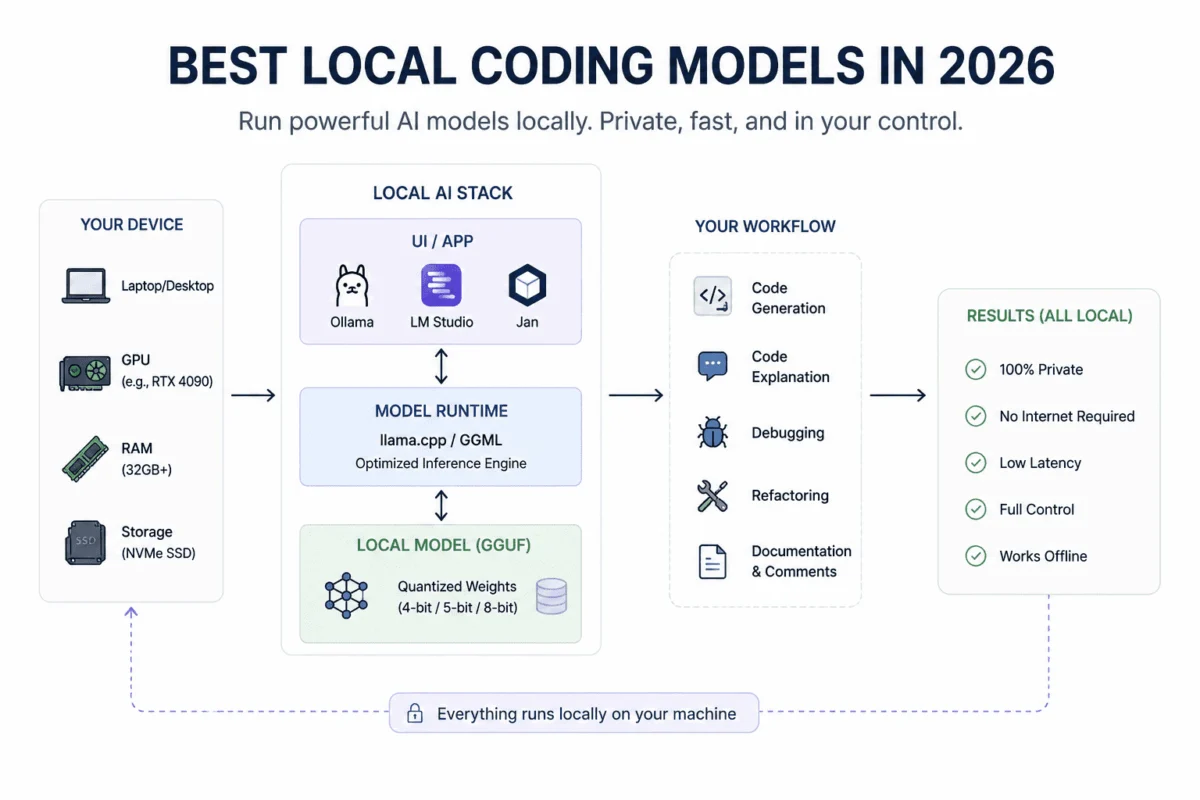
The modern data science landscape is increasingly characterized by complexity and scale, yet a significant portion of a data scientist’s valuable time remains dedicated to repetitive, formulaic tasks. Industry surveys consistently indicate that data professionals spend approximately 45% of their working hours on data preparation and cleaning—activities that, while crucial, often detract from more cognitively demanding tasks such as model development, insight generation, and strategic decision-making. This enduring bottleneck has spurred the adoption of advanced automation solutions, with agentic workflows emerging as a transformative paradigm to streamline the data science pipeline.
The Bottleneck of Manual Data Science
The persistent statistic—nearly half of a data scientist’s time consumed by data wrangling—underscores a fundamental challenge in the field. Tasks such as profiling column distributions, identifying and handling null values, conducting routine exploratory data analysis (EDA), meticulously tuning hyperparameters through grid searches, and implementing standard monitoring checks are inherently procedural. They follow explicit rules and patterns, making them ripe for automation. This manual overhead not only impacts productivity but also extends the time-to-insight, hindering an organization’s agility in leveraging data for competitive advantage.
Traditional automation tools have addressed parts of this problem, but the advent of large language models (LLMs) has introduced a new class of "agents." These AI entities are capable of reasoning, planning, and executing multi-step tasks, often leveraging external tools, much like a human would. This "agentic era" in data science signifies a shift from mere scripting to intelligent, context-aware automation that can adapt to varying data conditions and project requirements. Platforms like Databricks have already begun integrating such agentic capabilities into their core infrastructure, explicitly designing frameworks to compress the time from an initial question to actionable insight, reflecting a broader industry trend towards intelligent automation in production data teams.
The integration of agentic workflows does not aim to replace human data scientists but rather to augment their capabilities. By absorbing the "procedural weight" of data tasks, these agents enable data scientists to redirect their focus to the "evaluative weight"—critically assessing model efficacy, validating feature relevance, and determining the business implications of findings. This strategic reallocation of human expertise promises to unlock greater efficiency, consistency, and innovation within data science teams.
Pioneering Solutions: Five Key Agentic Workflows
The following five agentic workflows, each targeting a critical stage of the data science pipeline, illustrate how this paradigm can be implemented. Each workflow includes a real-world scenario, tested code patterns (which would be executed using Python 3.10+, pandas, scikit-learn, and an OpenAI-compatible LLM API), and key design considerations for production environments.
1. Automated Exploratory Data Analysis (EDA) Agent
Replacing: The repetitive, manual process of loading datasets, computing summary statistics, visualizing distributions, inspecting missing values, detecting outliers, and drafting initial findings for every new dataset. This often involves running largely identical scripts with only minor modifications for column names.
Agent’s Role: The EDA agent takes on the responsibility of ingesting the dataset, executing a comprehensive data profile, identifying potential data quality issues, classifying their severity, and synthesizing these observations into a structured Markdown report. A human data scientist then reviews this report, making informed decisions on subsequent data cleaning and transformation steps, free from the diagnostic legwork.
Architecture and Impact: This agent typically employs a Reasoning and Acting (ReAct) loop. It uses tools such as profile_dataset to generate detailed per-column statistics (e.g., data type, null rate, unique values, skewness, mean, standard deviation) and flag_issues to classify problems by severity (high, medium, low). A crucial design decision lies in how the agent processes the flag_issues output; it reasons about the actionability of issues, presenting a prioritized list rather than a raw dump. In a real-world scenario involving retail transaction data (5,000 rows, 8 columns), such an agent could flag extreme skew in ‘revenue’ (PSI > 0.25), a high null rate in ‘session_count’ (22%), and miscoded data types for ‘created_at’ (date as string). Within seconds, it would recommend a log transform for ‘revenue’, a null indicator feature for ‘session_count’, and parsing ‘created_at’ to extract temporal features. This rapid diagnostic capability significantly accelerates the initial understanding phase of any data project.
2. Agentic Feature Engineering and Selection
Replacing: The labor-intensive process of brainstorming interaction features, writing custom transformation code, individually evaluating each candidate feature with a baseline model, pruning those that offer no significant contribution, and meticulously documenting the rationale for retained features.
Agent’s Role: This agent proposes candidate features based on a structured data profile and the defined prediction task. It then generates the necessary transformation code, evaluates each candidate using a fast baseline model, and prunes features that fall below a configurable importance threshold. A written rationale accompanies each selection or pruning decision, offering transparency.
Architecture and Impact: This workflow operates in two phases, guided by a single agent. The generation phase utilizes an LLM to propose candidate features from dataset descriptions and the prediction task, providing a name, formula (pandas expression), and a rationale for each. The selection phase evaluates these candidates by training a LightGBM classifier with 5-fold cross-validation and computing feature importance using SHapley Additive exPlanations (SHAP). Features with importance scores below a set threshold are pruned. The agent’s reasoning component is vital here, as it can identify scenarios where a feature might appear weak globally but holds significant signal for a specific data segment. In a customer churn prediction scenario with 12 input columns, an agent could propose 15 candidates, including ‘spend_per_day’ and ‘tickets_per_spend_ratio’. After evaluation, 9 features might survive, with the agent highlighting ‘tickets_per_spend_ratio’ as having the highest importance (e.18), indicating a strong correlation between high spending customers who also raise many support tickets and churn risk. This insight is immediately actionable for product teams.

3. Agentic Hyperparameter Optimization
Replacing: Inefficient and often manual hyperparameter tuning methods such as exhaustive grid search (wasteful), random search (efficient but unguided), and boilerplate-heavy manual Bayesian optimization setups. These approaches typically treat tuning as a pure search problem.
Agent’s Role: An agent transforms hyperparameter tuning into a reasoning problem. It proposes a hyperparameter configuration, evaluates it by training the model, analyzes the metric trends across iterations, identifies parameters driving improvement, and intelligently adjusts its search direction. This approach converges on optimal configurations in significantly fewer iterations than traditional methods.
Architecture and Impact: This agent utilizes a single tool, train_and_evaluate, which accepts a Pydantic-validated hyperparameter configuration, trains the model with 5-fold cross-validation, and returns key metrics like AUC, training time, and overfitting gap. The agent, at each step, receives the full trial history and reasons about the next configuration to explore. Convergence is typically detected when the last few AUC scores show minimal variance (e.g., less than 0.005 over three iterations). Research has shown LLM-guided search outperforming Bayesian optimization by 5-12% on mid-sized classification tasks with fewer iterations. For a Census Income classification dataset (UCI, 48,842 rows), a default RandomForest might yield an AUC of 0.87. An agent-guided optimization could converge in 15 iterations to a configuration achieving AUC 0.91, providing transparent reasoning such as "max_depth appears to be the dominant driver… while n_estimators beyond 200 shows diminishing returns."
4. Automated Model Monitoring and Drift Detection Agent
Replacing: The manual, scheduled checking of feature distributions, the creation and maintenance of bespoke threshold rules for each column, and the delayed discovery of model degradation only after it impacts business metrics.
Agent’s Role: Operating on a defined schedule against incoming batch data, this agent computes drift statistics for each feature using established metrics like Population Stability Index (PSI) and the Kolmogorov-Smirnov (KS) test. It then classifies drift severity and responds dynamically: mild drift triggers an alert to the data science team, while severe drift automatically triggers a retraining pipeline.
Architecture and Impact: This is a scheduled agent built around the compute_drift_stats tool, which calculates PSI (a standard metric for population shift in production ML systems) and KS test statistics, classifying results as stable, mild drift, or severe drift. A PSI below 0.1 indicates stability, 0.1-0.25 suggests mild drift, and above 0.25 signifies severe drift warranting retraining. A single LLM call then determines the appropriate response: logging a passing check, drafting an alert for mild drift, or drafting an alert and triggering a retraining DAG (via Slack or Airflow REST API) for severe drift. This branching response mechanism, handled by the agent, eliminates the need for hardcoded if/else logic. In an e-commerce recommendation model scenario, a promotional event might cause session duration to jump from 180s to 310s and cart add rates to nearly triple. Running at midnight, the agent would detect PSI > 0.25 across all affected features, classify it as severe, and automatically trigger the retraining pipeline, simultaneously alerting the data science team to the issue and the proactive measures taken.
5. Agentic Pipeline Orchestration and Self-Healing
Replacing: The reactive, manual process of responding to Airflow (or similar orchestrator) failure notifications, delving into logs, deciphering tracebacks, determining the root cause (code, config, or transient error), applying a fix, and manually rerunning tasks, often with downstream dependencies failing in sequence.
Agent’s Role: This meta-agent operates above the existing orchestration layer. Upon an Airflow task failure, it receives the task ID, error log, and task definition. It then uses a tool to classify the error type deterministically, assesses if the error is auto-fixable, applies the necessary fix if it is, and either retriggers the task or escalates to a human with a fully structured incident report if manual intervention is required.
Architecture and Impact: The agent uses the parse_pipeline_error tool to categorize failures (e.g., schema_mismatch, null_violation, timeout, unknown). A subsequent LLM call decides on the auto-fixability and drafts either a fix description or an escalation report. For instance, if a daily feature pipeline fails at 2 AM because an upstream CRM system renamed transaction_date to txn_date_utc and added new columns, the agent would parse the KeyError for ‘transaction_date’, identify the schema mismatch, and propose an auto-fix: rename the column in the ingestion step and add the new columns as nullable. It would then log the fix, retrigger the task, and send a summary to the on-call engineer, allowing for review in the morning rather than an immediate emergency response. This proactive self-healing significantly reduces pipeline downtime and operational burden.
Strategic Implementation and Synergies
These five agentic workflows are not isolated tools but form a cohesive, intelligent pipeline. The EDA agent establishes data understanding, the feature engineering agent refines it, the hyperparameter agent optimizes models built upon these features, the monitoring agent safeguards the models in production, and the self-healing agent ensures the smooth operation of the entire data delivery mechanism.
A recommended deployment strategy involves a phased rollout. Starting with the monitoring agent offers immediate value to existing pipelines without requiring changes to core modeling code. The EDA agent can then be integrated for any new datasets. The feature engineering and hyperparameter optimization agents are best introduced once a stable baseline model is established and the focus shifts to iterative improvement.
Crucially, none of these workflows operate autonomously without human oversight for critical decisions. The EDA agent flags issues, but the data scientist decides the remediation. The feature agent proposes candidates, but the human sets importance thresholds. The hyperparameter agent explores, but the data scientist defines parameter bounds and convergence criteria. The monitoring agent detects drift, but the team defines severity thresholds for retraining. The self-healing agent applies fixes, which are subject to human review before merging into production. This deliberate division of labor, where agents manage procedural burdens and humans retain evaluative control, fosters a faster, more consistent, and robust data science pipeline. The result is a system where common failure points are detected and often resolved before human intervention is even necessary, allowing data scientists to truly focus on innovation and strategic impact.