The intricate world of machine learning (ML) and artificial intelligence (AI) has long grappled with challenges related to data consistency, feature reproducibility, and efficient model deployment. Many development teams encounter these hurdles the hard way: a predictive model that performs flawlessly in a controlled notebook environment often falters or "quietly breaks" when pushed to production, leading to inaccurate predictions or suboptimal user experiences. Similarly, inconsistencies arise when multiple ML pipelines independently calculate the same feature, such as a "30-day spend," only for discrepancies to emerge between their results. These operational inefficiencies and data integrity issues underscore a fundamental need for a robust data infrastructure component: the feature store. This essential system serves as a centralized repository and management layer for machine learning features, defining them once, storing them in optimized formats for both training and real-time serving, and meticulously keeping these representations synchronized.
The advent of sophisticated AI applications, particularly large language models (LLMs) and retrieval-augmented generation (RAG) pipelines, has dramatically expanded the imperative for such a system. These advanced models require granular, structured user context to deliver personalized and relevant outputs, often with stringent latency requirements. An LLM, inherently stateless, possesses no intrinsic memory of an individual user’s preferences or historical interactions. To enable personalized responses—whether recommending content, providing tailored support, or generating custom summaries—critical user attributes like plan tier, recent activity patterns, or account status must be dynamically injected into the model’s prompt. This necessitates a system capable of retrieving these values rapidly and consistently, a capability precisely fulfilled by a feature store’s online serving layer and retrieval API.
A recent practical demonstration illustrates the core principles of building such a system from the ground up. Utilizing a lean technology stack comprising Python, DuckDB, Parquet, Redis, and FastAPI, developers can construct a functional, minimal feature store. This architectural blueprint not only addresses traditional ML challenges like training-serving skew but also caters to the emergent demands of AI applications. The entire codebase for such an implementation is remarkably concise, allowing for a thorough examination of each component and its contribution to a resilient AI infrastructure.
Addressing the Core Problem: Training-Serving Skew and Beyond

Historically, the primary motivation for feature stores stemmed from the pervasive problem of "training-serving skew." This phenomenon occurs when the data used to train an ML model differs systematically from the data presented to the model during inference. Often, the SQL queries or data transformation logic employed to construct a training dataset are distinct from the code paths executed in a real-time production environment. This divergence can lead to feature values "drifting" between training and serving, ultimately degrading model performance and reliability. The feature store’s fundamental solution involves maintaining an "offline" store for historical training data and an "online" store for real-time inference data, ensuring both are derived from a single, consistent definition and kept synchronized.
However, the modern utility of feature stores extends far beyond mitigating training-serving skew. The transformative rise of LLMs and generative AI has introduced new, critical requirements for real-time contextualization. Imagine a scenario where a customer support agent powered by an LLM needs to understand a user’s subscription level, recent product usage, and historical support interactions to provide a truly helpful and personalized response. This structured user context must be fetched and injected into the LLM’s prompt within milliseconds to maintain a fluid conversational experience. The feature store, with its low-latency online retrieval capabilities, is ideally positioned to supply this critical information, transforming generic LLM outputs into highly tailored and effective interactions. This dual capability—supporting both traditional predictive ML models and context-hungry generative AI applications—underscores the feature store’s evolving and expanding role as a cornerstone of modern data platforms.
The Foundational Five: Deconstructing the Feature Store Architecture
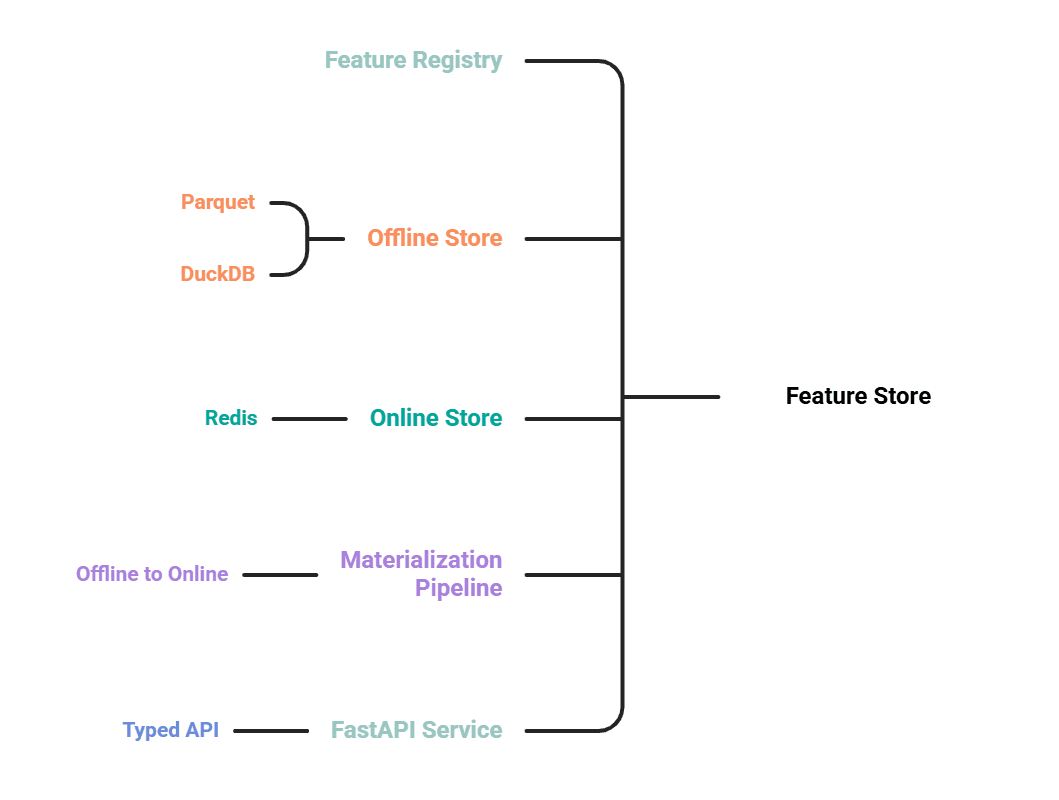
A feature store, whether a minimal custom build or an enterprise-grade platform, fundamentally comprises five interconnected components, each playing a vital role in ensuring data consistency and efficient feature delivery:
-
The Feature Registry: At its heart, the feature registry acts as the single source of truth for all defined features. It’s where features are declared once, specifying their name, the entity they describe (e.g.,
user_id,product_id), their data type, and their underlying data source. In a production environment, this registry might be managed via YAML files or a Python module committed to a version-controlled Git repository, enforcing strict code review for any changes. This centralized definition ensures that every downstream component—from offline data pipelines to online serving APIs—references the same authoritative metadata, preventing discrepancies and fostering collaboration across data science and engineering teams. The registry’s immutability, often achieved throughfrozen=Truedataclasses in Python, reinforces its role as a stable contract for feature definitions.
-
The Offline Store (Training and Backfill): This component is responsible for storing the complete historical record of every feature value. It serves as the authoritative source for generating training datasets, performing historical analyses, and auditing feature values over time. For efficiency and scalability, columnar storage formats like Parquet are frequently employed, offering excellent compression and query performance for analytical workloads. DuckDB, an in-process analytical database, emerges as a powerful choice for querying these Parquet files directly, eliminating the need for a separate, complex database server. A critical function of the offline store is the "point-in-time join" (often an Asof join), which ensures that when constructing a training example, only feature values that existed prior to the event timestamp are included. This mechanism is paramount in preventing data leakage, where future information inadvertently contaminates a training sample, leading to overly optimistic model performance in development that fails to materialize in production. While direct LLM inference might not always query the offline store, its role in model training, evaluation, and data integrity remains indispensable.
-
The Online Store (Real-time Serving): Designed for low-latency, high-throughput retrieval, the online store holds only the latest feature value for each entity. Its primary purpose is to serve feature values to models and AI applications during real-time inference. Redis, an in-memory data structure store, is a de facto standard for this component due to its exceptional performance characteristics, capable of delivering sub-millisecond hash lookups. Features are typically stored as key-value pairs, where the key represents the entity (
entity:entity_id) and the value is a hash containing all features for that entity. This structure allows for retrieving multiple features for a single entity in a single network round trip, optimizing latency crucial for real-time applications like personalized recommenders or conversational AI. -
The Materialization Pipeline: This is the operational backbone that bridges the offline and online stores. The materialization pipeline is responsible for transforming and moving feature values from their raw sources or the offline store into the online store. In production systems, this process is automated and scheduled, often orchestrated by tools like Airflow or cron jobs, or even through real-time streaming platforms. The pipeline typically involves querying the latest feature values from the offline store or raw data sources, often using SQL constructs like
QUALIFY ROW_NUMBER() OVER (PARTITION BY entity ORDER BY event_timestamp DESC) = 1to select the most recent record per entity. These processed values are then written to the online store, typically grouped by entity to minimize network round trips. The cadence of materialization varies per feature, reflecting its freshness requirements—daily for slowly changing attributes, hourly for more dynamic ones, and near real-time for highly volatile features. -
The Retrieval Service (API): The retrieval service is the public-facing interface of the feature store, providing a simple and fast API endpoint for consuming applications to request features. It abstracts away the underlying storage mechanisms, allowing ML models, LLM agents, and other applications to fetch the required context without needing to understand the intricacies of the feature store’s internal workings. Frameworks like FastAPI are excellent choices for building these services, offering high performance and ease of development. For an LLM-powered recommender, for example, the application would call this API with a
user_id, and the service would return a structured dictionary of features (e.g.,user_segment,watch_count_30d,last_genre), which can then be seamlessly injected into the LLM’s prompt. This service transforms a mere identifier into rich, actionable context for the AI.
A Practical Illustration: The Personalized LLM Recommender
Consider a streaming service aiming to provide highly personalized content recommendations using an LLM. When a user opens the application, the LLM needs immediate, specific context about that user to generate a tailored "what to watch next" message. For this, three key features are identified: user_segment (e.g., ‘power_user’, ‘casual’), watch_count_30d, and last_genre. These features, all tied to the user_id entity, demonstrate varying freshness requirements: user_segment might be updated daily, watch_count_30d hourly, and last_genre per event (near real-time).
The feature registry defines these features, specifying their entity, data type, and source file (e.g., data/user_segment.parquet). The offline store, powered by DuckDB and Parquet, can then generate historical datasets for model training or analysis, correctly applying point-in-time joins to prevent data leakage. The materialization pipeline periodically fetches the latest values for these features and pushes them to the Redis-backed online store. Finally, when the user opens the app, the LLM application calls the FastAPI retrieval service with the user_id, receiving an immediate, structured context like: "User context: segment=power_user, watched 47 titles in last 30 days, last genre watched: documentary." This context is then used to craft a highly relevant prompt for the LLM, enabling it to suggest personalized titles.
Feature Stores vs. Vector Databases: Complementary Powerhouses
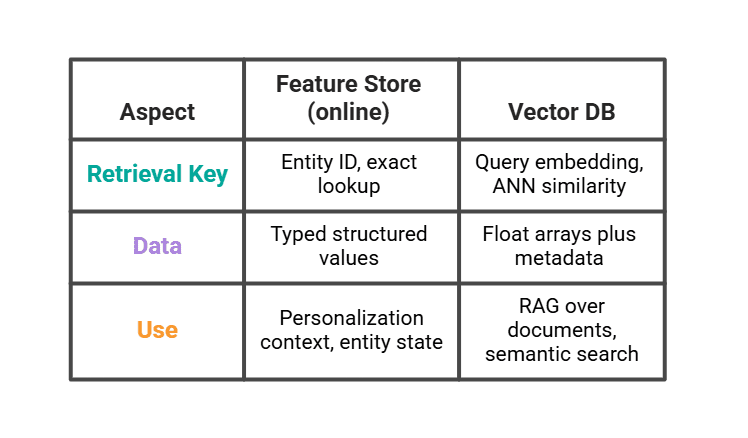
It is crucial to differentiate feature stores from vector databases, despite both serving as critical retrieval layers for AI models. While both reside in front of a model at inference time, they solve distinct types of retrieval problems. A feature store excels at managing and serving structured, tabular data—discrete facts about entities (e.g., a user’s age, purchase history count, subscription status). Its strength lies in providing precise, factual attributes.
In contrast, a vector database (like Pinecone, Weaviate, or pgvector) is designed for handling unstructured or semi-structured data by converting it into high-dimensional numerical representations called embeddings. It specializes in semantic search and similarity matching. For instance, a vector database might return the three most semantically similar past viewing sessions for a user, or retrieve relevant document chunks based on a query’s meaning.
In a sophisticated LLM stack, these two systems are complementary. The vector database might retrieve relevant historical content or knowledge bases based on the user’s current query or interaction, while the feature store simultaneously provides structured user attributes. The LLM then combines insights from both sources—the semantic context from the vector database and the factual context from the feature store—to generate a more informed, nuanced, and personalized response. Neither replaces the other; instead, they collaborate to provide a comprehensive context for advanced AI.
The Evolving Landscape of Commercial Feature Stores
While building a minimal feature store from scratch offers invaluable insights into its core mechanics, the industry has seen the emergence of robust commercial and open-source platforms designed to handle enterprise-scale requirements. Open-source solutions like Feast provide a solid foundation for self-hosted deployments, offering many of the features demonstrated in a minimal build, but with added capabilities for governance, monitoring, and integration with broader MLOps ecosystems.
Managed platforms like Tecton and Databricks represent the fully-featured, enterprise-grade end of the spectrum. Tecton, for instance, offers a dedicated Feature Retrieval API for LLMs, emphasizing seamless integration with generative AI workflows. Databricks, with its integrated Lakehouse platform, provides Feature Serving capabilities tailored for compound generative AI systems, leveraging its existing data management and processing infrastructure. The choice between building a custom minimal solution and adopting a commercial platform often hinges on factors such as organizational resources for maintenance, scalability requirements, existing technology stack (e.g., heavy investment in Databricks), and the need for advanced features like automated data quality checks, drift detection, and comprehensive access control. Industry trends indicate a growing preference for managed solutions that abstract away operational complexities, allowing data scientists and engineers to focus on feature engineering and model development rather than infrastructure management.
Challenges and Best Practices in Feature Store Implementation
Implementing a feature store, even a minimal one, requires careful consideration of several potential pitfalls and adherence to best practices:
- Data Governance and Ownership: A common anti-pattern is the lack of clear ownership and inconsistent definitions for features. A robust feature registry, coupled with strong organizational processes, is essential to establish a single, authoritative definition for each feature, preventing "shadow features" and ensuring data quality.
- Scalability and Performance: While Redis excels for online serving, ensuring the offline store and materialization pipelines can scale with growing data volumes and feature complexity is critical. Designing for distributed processing and efficient data formats (like Parquet) is paramount.
- Operational Complexity: Manual feature engineering and materialization processes are unsustainable. Automation of feature creation, transformation, and ingestion into both online and offline stores is crucial for maintaining feature freshness and reducing operational burden.
- Feature Versioning and Lineage: In a dynamic environment, features evolve. Implementing mechanisms for versioning features and tracking their lineage—from raw data source to final consumption—is vital for reproducibility, debugging, and auditability.
- Monitoring and Alerting: Without robust monitoring of data quality, feature freshness, and retrieval latency, a feature store can silently fail. Implementing dashboards and alerts for data drift, schema changes, and performance bottlenecks is a best practice.
Conclusion and Future Outlook
The construction of a working feature store, even in its most minimal form, offers profound insights into the foundational infrastructure required for reliable and scalable AI and machine learning systems. Its five core components—the registry, offline store, online store, materialization pipeline, and retrieval API—collectively address critical challenges like data consistency, training-serving skew, and the real-time contextualization demands of modern AI. The exercise of building such a system clarifies why production-grade platforms are designed the way they are, highlighting the specific architectural choices driven by performance, scalability, and data integrity requirements.
Furthermore, this exploration illuminates how the design considerations for feature stores adapt to the AI paradigm shift. The online retrieval path has become the critical interface for LLM applications, demanding ultra-low latency. Point-in-time joins remain indispensable for accurate model training and evaluation, irrespective of the downstream model type. Crucially, it establishes the clear, yet complementary, roles of feature stores and vector databases within a sophisticated AI stack, each addressing distinct retrieval challenges. The knowledge gained from a minimal implementation serves as an invaluable springboard. Should an organization decide to scale beyond a custom build, transitioning to robust open-source solutions like Feast or enterprise platforms like Tecton or Databricks becomes primarily a migration of the feature registry and data pipelines. The fundamental architectural shape and the underlying principles of consistent, performant feature management remain steadfast, underscoring the enduring relevance of feature stores as an indispensable pillar of contemporary AI and ML engineering. The work of practitioners like Nate Rosidi, through practical guides, continues to empower teams to navigate this complex landscape with clarity and efficiency.